注意
点击此处下载完整示例代码
2. 深入探讨 CIFAR10 训练¶
希望您享受了我们的演示脚本。现在,您可能想知道:模型究竟是如何训练的?在本教程中,我们将重点回答这个问题。
前提条件¶
我们假设读者对 Gluon 有基本了解。如果没有,建议您花 60 分钟阅读 Gluon 速成课程入门。
众所周知,在 GPU 上训练深度神经网络比在 CPU 上快得多。在之前的教程中,我们使用了 CPU,因为对单张图像进行分类相对容易。然而,既然我们要训练模型,强烈建议使用带 GPU 的机器。
注意
本教程的其余部分将引导您详细了解 CIFAR10 训练。如果您想快速入门而无需了解细节,可以下载此脚本,然后只需一个命令即可开始训练。
以下是带推荐参数的示例命令
网络结构¶
首先,让我们导入必要的库到 python 中。
from __future__ import division
import argparse, time, logging, random, math
import numpy as np
import mxnet as mx
from mxnet import gluon, nd
from mxnet import autograd as ag
from mxnet.gluon import nn
from mxnet.gluon.data.vision import transforms
from gluoncv.model_zoo import get_model
from gluoncv.utils import makedirs, TrainingHistory
from gluoncv.data import transforms as gcv_transforms
卷积神经网络有多种结构。本教程选择了一个简单但性能良好的结构,cifar_resnet20_v1。
数据增强和数据加载器¶
数据增强是训练中常用的技术。它基于这样的假设:对于同一物体,在不同构图、光照条件或颜色下的照片都应该得到相同的预测。
以下是金门大桥的照片,由许多人在不同时间从不同角度拍摄。我们可以很容易地看出它们是同一个地方的照片。
我们希望通过“增强”输入图像,将这种不变性教给我们的模型。我们的增强会通过调整大小、裁剪、翻转等技术转换图像。
使用 Gluon,我们可以创建如下转换函数:
transform_train = transforms.Compose([
# Randomly crop an area and resize it to be 32x32, then pad it to be 40x40
gcv_transforms.RandomCrop(32, pad=4),
# Randomly flip the image horizontally
transforms.RandomFlipLeftRight(),
# Transpose the image from height*width*num_channels to num_channels*height*width
# and map values from [0, 255] to [0,1]
transforms.ToTensor(),
# Normalize the image with mean and standard deviation calculated across all images
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
您可能已经注意到,大多数操作都是随机的。这实际上增加了模型在训练期间看到的图像数量。数据越多,我们的模型对未见图像的泛化能力就越好。
另一方面,进行预测时,我们希望移除所有随机操作以获得确定性结果。预测的转换函数如下:
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
请注意,保持归一化步骤很重要,因为模型仅在来自相同分布的输入上表现良好。
有了转换函数,我们可以为训练和验证数据集定义数据加载器。
# Batch Size for Each GPU
per_device_batch_size = 128
# Number of data loader workers
num_workers = 8
# Calculate effective total batch size
batch_size = per_device_batch_size * num_gpus
# Set train=True for training data
# Set shuffle=True to shuffle the training data
train_data = gluon.data.DataLoader(
gluon.data.vision.CIFAR10(train=True).transform_first(transform_train),
batch_size=batch_size, shuffle=True, last_batch='discard', num_workers=num_workers)
# Set train=False for validation data
val_data = gluon.data.DataLoader(
gluon.data.vision.CIFAR10(train=False).transform_first(transform_test),
batch_size=batch_size, shuffle=False, num_workers=num_workers)
输出
Downloading /root/.mxnet/datasets/cifar10/cifar-10-binary.tar.gz from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/dataset/cifar10/cifar-10-binary.tar.gz...
优化器、损失函数和指标¶
优化器在训练期间改进模型。这里我们使用流行的 Nesterov 加速梯度下降算法。
# Learning rate decay factor
lr_decay = 0.1
# Epochs where learning rate decays
lr_decay_epoch = [80, 160, np.inf]
# Nesterov accelerated gradient descent
optimizer = 'nag'
# Set parameters
optimizer_params = {'learning_rate': 0.1, 'wd': 0.0001, 'momentum': 0.9}
# Define our trainer for net
trainer = gluon.Trainer(net.collect_params(), optimizer, optimizer_params)
在上面的代码中,lr_decay 和 lr_decay_epoch 并未直接在 trainer 中使用。模型训练中的一个重要思想是逐步降低学习率。这意味着优化器最初会迈大步,但步长会随着时间变得越来越小。
我们的计划是将学习率开始时设置为 0.1,然后在第 80 个 epoch 将其除以 10,在第 160 个 epoch 再次除以 10。我们将在主训练循环中使用 lr_decay_epoch 实现此目的。
为了优化我们的模型,我们需要一个损失函数。本质上,损失函数计算预测值与真实值之间的差异作为模型性能的度量。然后我们可以计算损失函数关于权重的梯度。梯度会指向优化器应该移动权重的方向以提高模型性能。
对于分类任务,我们通常使用 softmax 交叉熵作为损失函数。
loss_fn = gluon.loss.SoftmaxCrossEntropyLoss()
指标与损失函数类似,但它们在以下方面有所不同:
指标是我们评估模型性能的方式。每个指标都与特定任务相关,但独立于模型训练过程。
对于分类任务,我们通常只使用一个损失函数来训练模型,但可以使用多个指标来评估性能。
损失函数可以用作指标,但有时其值难以解释。例如,“准确率”的概念比“softmax 交叉熵”更容易理解。
为简单起见,我们使用准确率作为指标来监控训练过程。此外,我们记录指标值,并在训练结束时打印出来。
train_metric = mx.metric.Accuracy()
train_history = TrainingHistory(['training-error', 'validation-error'])
验证¶
验证数据集提供了监控训练过程的方法。我们有验证数据的标签,但在训练期间不使用它们。相反,我们用它们来评估模型在未见数据上的性能并防止过拟合。
def test(ctx, val_data):
metric = mx.metric.Accuracy()
for i, batch in enumerate(val_data):
data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0)
label = gluon.utils.split_and_load(batch[1], ctx_list=ctx, batch_axis=0)
outputs = [net(X) for X in data]
metric.update(label, outputs)
return metric.get()
为了评估性能,我们需要一个指标。然后,我们遍历验证数据并使用模型进行预测。我们将在每个 epoch 结束时运行此函数以显示相对于上一个 epoch 的改进。
训练¶
经过所有准备,我们终于可以开始训练了!以下是脚本。
注意
为了快速完成本教程,我们只训练 3 个 epoch。在您的实验中,我们建议设置 epochs=240。
epochs = 3
lr_decay_count = 0
for epoch in range(epochs):
tic = time.time()
train_metric.reset()
train_loss = 0
# Learning rate decay
if epoch == lr_decay_epoch[lr_decay_count]:
trainer.set_learning_rate(trainer.learning_rate*lr_decay)
lr_decay_count += 1
# Loop through each batch of training data
for i, batch in enumerate(train_data):
# Extract data and label
data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0)
label = gluon.utils.split_and_load(batch[1], ctx_list=ctx, batch_axis=0)
# AutoGrad
with ag.record():
output = [net(X) for X in data]
loss = [loss_fn(yhat, y) for yhat, y in zip(output, label)]
# Backpropagation
for l in loss:
l.backward()
# Optimize
trainer.step(batch_size)
# Update metrics
train_loss += sum([l.sum().asscalar() for l in loss])
train_metric.update(label, output)
name, acc = train_metric.get()
# Evaluate on Validation data
name, val_acc = test(ctx, val_data)
# Update history and print metrics
train_history.update([1-acc, 1-val_acc])
print('[Epoch %d] train=%f val=%f loss=%f time: %f' %
(epoch, acc, val_acc, train_loss, time.time()-tic))
# We can plot the metric scores with:
train_history.plot()
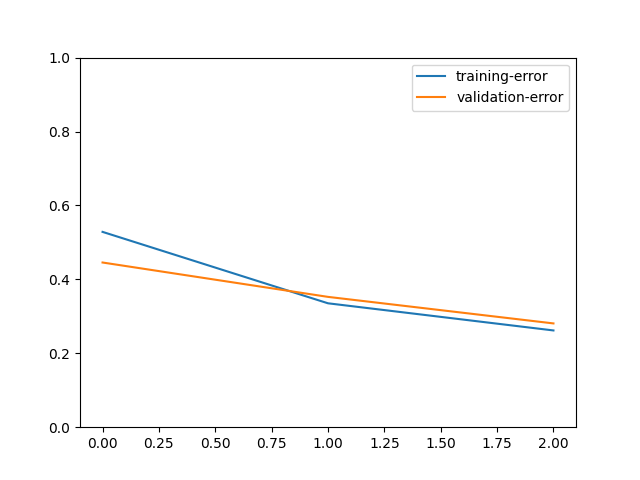
输出
[Epoch 0] train=0.471534 val=0.554400 loss=72228.913193 time: 15.000804
[Epoch 1] train=0.664764 val=0.647400 loss=47040.039818 time: 14.944686
[Epoch 2] train=0.738221 val=0.719200 loss=37378.394009 time: 15.093496
如果您将模型训练了 240 个 epoch,图表可能如下所示:
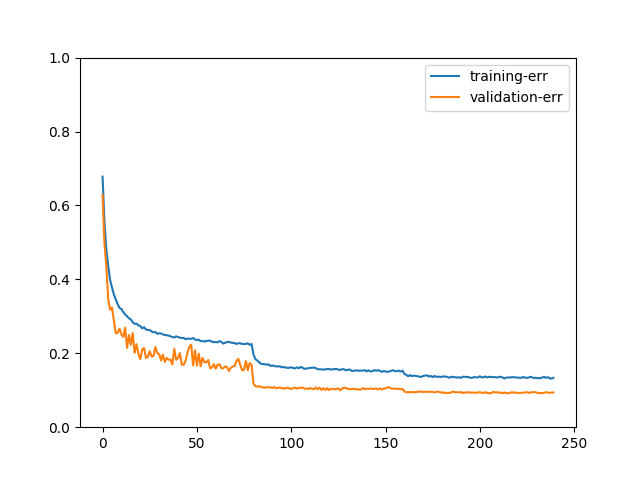
我们可以通过图表更好地观察模型训练过程。例如,有人可能会问,如果没有数据增强会发生什么?
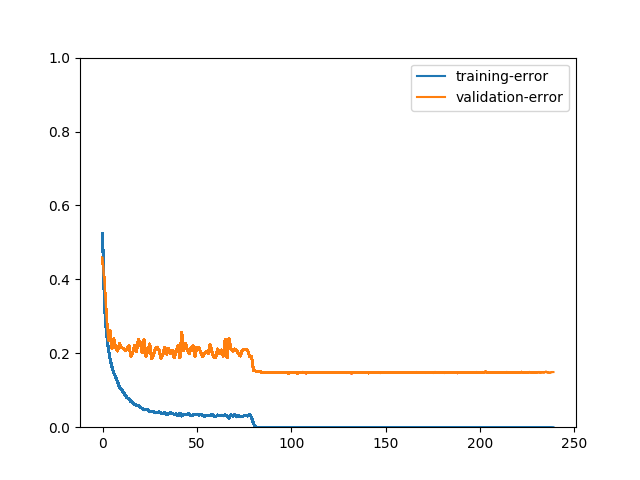
我们可以看到训练误差远低于验证误差。模型在训练数据上达到 100% 准确率后,在验证数据上停止改进。这两张图表清晰地展示了数据增强的重要性。
模型保存与加载¶
训练后,我们通常希望保存模型以备将来使用。只需通过以下方式完成:
net.save_parameters('dive_deep_cifar10_resnet20_v2.params')
下次您需要使用它时,只需运行:
下一步¶
这是我们与 CIFAR10 冒险的结束,但计算机视觉中还有更多数据集和算法!
如果您想了解如何在比 CIFAR10 大得多的数据集(例如 ImageNet)上训练模型,请阅读ImageNet 训练。
或者,如果您想了解如何使用您刚训练的模型,请阅读关于迁移学习的教程。
脚本总运行时间: ( 0 分 51.571 秒)