注意
点击此处下载完整的示例代码
08. 微调预训练检测模型¶
微调是一种常用的方法,用于将先前训练的模型迁移到新的数据集上。如果目标新数据集相对较小,这种方法尤其有用。
从预训练模型进行微调有助于减少过拟合的风险。如果先前使用的数据集与新数据集的领域相似,微调后的模型泛化能力也可能更好。
本教程提供了一种微调 GluonCV 提供的目标检测模型的好方法。更具体地说,我们将展示如何使用定制的皮卡丘数据集,并逐步说明微调的基础知识。您将熟悉这些步骤,并可以修改它以适应您自己的目标检测项目。
import time
from matplotlib import pyplot as plt
import numpy as np
import mxnet as mx
from mxnet import autograd, gluon
import gluoncv as gcv
from gluoncv.utils import download, viz
皮卡丘数据集¶
首先,我们将从一个不错的皮卡丘数据集开始,该数据集是通过在随机真实世界场景中渲染 3D 模型生成的。您可以参考为目标检测准备自定义数据集了解如何创建自己的数据集。
输出
Downloading pikachu_train.rec from https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/pikachu/train.rec...
0%| | 0/85604 [00:00<?, ?KB/s]
0%| | 99/85604 [00:00<01:42, 831.29KB/s]
1%| | 516/85604 [00:00<00:35, 2398.94KB/s]
3%|2 | 2183/85604 [00:00<00:10, 7664.70KB/s]
10%|9 | 8264/85604 [00:00<00:02, 26420.86KB/s]
18%|#7 | 15012/85604 [00:00<00:01, 40183.06KB/s]
27%|##6 | 23009/85604 [00:00<00:01, 53062.78KB/s]
37%|###7 | 31770/85604 [00:00<00:00, 63987.92KB/s]
47%|####6 | 39867/85604 [00:00<00:00, 69271.13KB/s]
56%|#####6 | 48328/85604 [00:00<00:00, 73947.12KB/s]
66%|######6 | 56677/85604 [00:01<00:00, 76859.18KB/s]
76%|#######5 | 64851/85604 [00:01<00:00, 78331.42KB/s]
86%|########5 | 73374/85604 [00:01<00:00, 80412.73KB/s]
95%|#########5| 81454/85604 [00:01<00:00, 80501.35KB/s]
85605KB [00:01, 60629.71KB/s]
Downloading pikachu_train.idx from https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/pikachu/train.idx...
0%| | 0/11 [00:00<?, ?KB/s]
12KB [00:00, 11259.88KB/s]
我们可以使用 RecordFileDetection 加载数据集
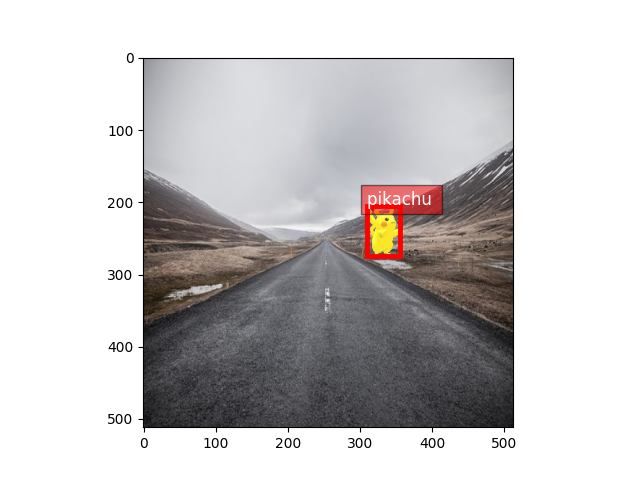
输出
label: [[309.6292 205.79944 355.75494 274.14044 0. ]]
预训练模型¶
现在我们可以获取一个预训练模型进行微调。我们有许多模型可供选择,来自检测模型库。再次为了演示目的,我们选择了一个使用 MobileNet1.0 主干网络的快速 SSD 网络。
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_voc', pretrained=True)
输出
/usr/local/lib/python3.6/dist-packages/mxnet/gluon/block.py:1512: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
Downloading /root/.mxnet/models/ssd_512_mobilenet1.0_voc-37c18076.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/ssd_512_mobilenet1.0_voc-37c18076.zip...
0%| | 0/50216 [00:00<?, ?KB/s]
0%| | 93/50216 [00:00<01:07, 740.10KB/s]
1%|1 | 518/50216 [00:00<00:21, 2281.86KB/s]
4%|4 | 2180/50216 [00:00<00:06, 7238.43KB/s]
16%|#5 | 7805/50216 [00:00<00:01, 23914.26KB/s]
28%|##8 | 14220/50216 [00:00<00:00, 37073.82KB/s]
45%|####4 | 22564/50216 [00:00<00:00, 51838.35KB/s]
60%|#####9 | 30022/50216 [00:00<00:00, 58948.02KB/s]
76%|#######6 | 38257/50216 [00:00<00:00, 64740.74KB/s]
93%|#########2| 46642/50216 [00:00<00:00, 70499.45KB/s]
50217KB [00:01, 48530.14KB/s]
重置网络以预测皮卡丘!
net.reset_class(classes)
# now the output layers that used to map to VOC classes are now reset to distinguish pikachu (and background).
有一个方便的 API 用于创建带有预训练权重的自定义网络。这等同于加载预训练模型并调用 net.reset_class。
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_custom', classes=classes,
pretrained_base=False, transfer='voc')
输出
/usr/local/lib/python3.6/dist-packages/mxnet/gluon/block.py:1512: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
通过加载完全预训练的模型,您不仅加载了基础网络权重(例如 MobileNet),还加载了专门用于目标检测的一些额外块。
来自检测任务的预训练模型比pretrained_base网络(通常在 ImageNet 上训练用于图像分类任务)更相关和更具适应性。
因此,在某些情况下,微调可能会显著更快更好地收敛。
微调是新一轮训练¶
提示
您可以在此处找到更详细的 SSD 训练实现:下载 train_ssd.py
def get_dataloader(net, train_dataset, data_shape, batch_size, num_workers):
from gluoncv.data.batchify import Tuple, Stack, Pad
from gluoncv.data.transforms.presets.ssd import SSDDefaultTrainTransform
width, height = data_shape, data_shape
# use fake data to generate fixed anchors for target generation
with autograd.train_mode():
_, _, anchors = net(mx.nd.zeros((1, 3, height, width)))
batchify_fn = Tuple(Stack(), Stack(), Stack()) # stack image, cls_targets, box_targets
train_loader = gluon.data.DataLoader(
train_dataset.transform(SSDDefaultTrainTransform(width, height, anchors)),
batch_size, True, batchify_fn=batchify_fn, last_batch='rollover', num_workers=num_workers)
return train_loader
train_data = get_dataloader(net, dataset, 512, 16, 0)
尝试使用 GPU 进行训练
开始训练(微调)
net.collect_params().reset_ctx(ctx)
trainer = gluon.Trainer(
net.collect_params(), 'sgd',
{'learning_rate': 0.001, 'wd': 0.0005, 'momentum': 0.9})
mbox_loss = gcv.loss.SSDMultiBoxLoss()
ce_metric = mx.metric.Loss('CrossEntropy')
smoothl1_metric = mx.metric.Loss('SmoothL1')
for epoch in range(0, 2):
ce_metric.reset()
smoothl1_metric.reset()
tic = time.time()
btic = time.time()
net.hybridize(static_alloc=True, static_shape=True)
for i, batch in enumerate(train_data):
batch_size = batch[0].shape[0]
data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0)
cls_targets = gluon.utils.split_and_load(batch[1], ctx_list=ctx, batch_axis=0)
box_targets = gluon.utils.split_and_load(batch[2], ctx_list=ctx, batch_axis=0)
with autograd.record():
cls_preds = []
box_preds = []
for x in data:
cls_pred, box_pred, _ = net(x)
cls_preds.append(cls_pred)
box_preds.append(box_pred)
sum_loss, cls_loss, box_loss = mbox_loss(
cls_preds, box_preds, cls_targets, box_targets)
autograd.backward(sum_loss)
# since we have already normalized the loss, we don't want to normalize
# by batch-size anymore
trainer.step(1)
ce_metric.update(0, [l * batch_size for l in cls_loss])
smoothl1_metric.update(0, [l * batch_size for l in box_loss])
name1, loss1 = ce_metric.get()
name2, loss2 = smoothl1_metric.get()
if i % 20 == 0:
print('[Epoch {}][Batch {}], Speed: {:.3f} samples/sec, {}={:.3f}, {}={:.3f}'.format(
epoch, i, batch_size/(time.time()-btic), name1, loss1, name2, loss2))
btic = time.time()
输出
[Epoch 0][Batch 0], Speed: 8.521 samples/sec, CrossEntropy=11.958, SmoothL1=1.986
[Epoch 0][Batch 20], Speed: 19.758 samples/sec, CrossEntropy=4.358, SmoothL1=1.233
[Epoch 0][Batch 40], Speed: 21.477 samples/sec, CrossEntropy=3.299, SmoothL1=0.968
[Epoch 1][Batch 0], Speed: 20.556 samples/sec, CrossEntropy=1.529, SmoothL1=0.308
[Epoch 1][Batch 20], Speed: 19.868 samples/sec, CrossEntropy=1.613, SmoothL1=0.454
[Epoch 1][Batch 40], Speed: 19.864 samples/sec, CrossEntropy=1.577, SmoothL1=0.453
将微调后的权重保存到磁盘
net.save_parameters('ssd_512_mobilenet1.0_pikachu.params')
使用微调模型进行预测¶
我们可以使用微调后的权重测试性能
test_url = 'https://raw.githubusercontent.com/zackchase/mxnet-the-straight-dope/master/img/pikachu.jpg'
download(test_url, 'pikachu_test.jpg')
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_custom', classes=classes, pretrained_base=False)
net.load_parameters('ssd_512_mobilenet1.0_pikachu.params')
x, image = gcv.data.transforms.presets.ssd.load_test('pikachu_test.jpg', 512)
cid, score, bbox = net(x)
ax = viz.plot_bbox(image, bbox[0], score[0], cid[0], class_names=classes)
plt.show()
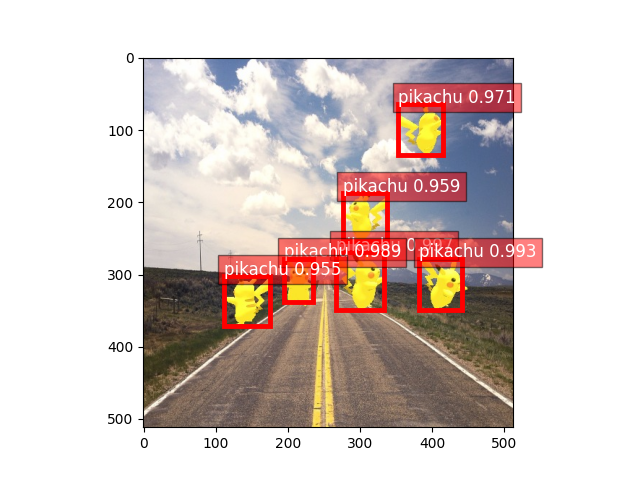
输出
Downloading pikachu_test.jpg from https://raw.githubusercontent.com/zackchase/mxnet-the-straight-dope/master/img/pikachu.jpg...
0%| | 0/88 [00:00<?, ?KB/s]
89KB [00:00, 19654.24KB/s]
/usr/local/lib/python3.6/dist-packages/mxnet/gluon/block.py:1512: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
在两个 epoch 和不到 5 分钟的时间里,我们能够完美地检测到皮卡丘!
脚本总运行时间: ( 1 分 33.133 秒)