注意
点击此处下载完整示例代码
04. 在Pascal VOC数据集上训练SSD¶
本教程介绍了GluonCV提供的目标检测基本构建模块。具体来说,我们将展示如何通过堆叠GluonCV组件构建一个最先进的单发多框检测 (Single Shot Multibox Detection) [Liu16] 模型。这也是您自己的目标检测项目的一个良好起点。
提示
您可以跳过本教程的其余部分,直接下载此脚本开始训练您的SSD模型
使用示例
在GPU 0上使用Pascal VOC训练默认的vgg16_atrous 300x300模型
python train_ssd.py
在GPU 0,1,2,3上训练resnet50_v1 512x512模型
python train_ssd.py --gpus 0,1,2,3 --network resnet50_v1 --data-shape 512
检查支持的参数
python train_ssd.py --help
数据集¶
请首先阅读这篇 准备PASCAL VOC数据集 教程,在您的磁盘上设置Pascal VOC数据集。然后,我们就可以加载训练和验证图像了。
from gluoncv.data import VOCDetection
# typically we use 2007+2012 trainval splits for training data
train_dataset = VOCDetection(splits=[(2007, 'trainval'), (2012, 'trainval')])
# and use 2007 test as validation data
val_dataset = VOCDetection(splits=[(2007, 'test')])
print('Training images:', len(train_dataset))
print('Validation images:', len(val_dataset))
输出
Training images: 16551
Validation images: 4952
数据转换¶
我们可以从训练数据集中读取一对图像-标签
train_image, train_label = train_dataset[0]
bboxes = train_label[:, :4]
cids = train_label[:, 4:5]
print('image:', train_image.shape)
print('bboxes:', bboxes.shape, 'class ids:', cids.shape)
输出
image: (375, 500, 3)
bboxes: (5, 4) class ids: (5, 1)
绘制图像以及边界框标签
from matplotlib import pyplot as plt
from gluoncv.utils import viz
ax = viz.plot_bbox(
train_image.asnumpy(),
bboxes,
labels=cids,
class_names=train_dataset.classes)
plt.show()
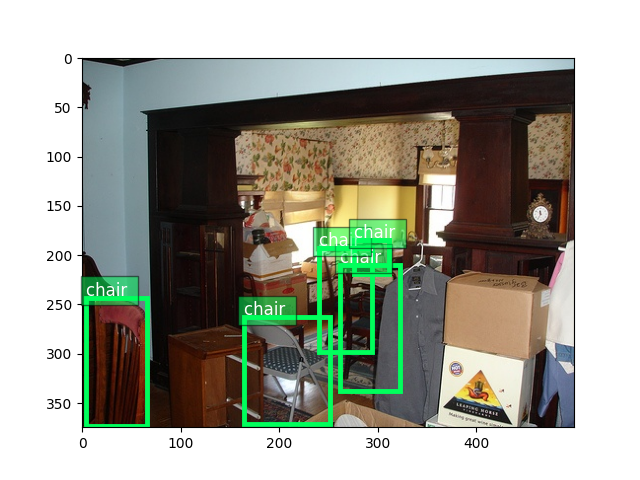
验证图像与训练图像非常相似,因为它们基本上是随机划分到不同集合中的
val_image, val_label = val_dataset[0]
bboxes = val_label[:, :4]
cids = val_label[:, 4:5]
ax = viz.plot_bbox(
val_image.asnumpy(),
bboxes,
labels=cids,
class_names=train_dataset.classes)
plt.show()

对于SSD网络,应用数据增强至关重要(详见论文[Liu16]中的解释)。我们提供了大量的图像和边界框转换函数来实现这一点。它们也非常方便使用。
from gluoncv.data.transforms import presets
from gluoncv import utils
from mxnet import nd
width, height = 512, 512 # suppose we use 512 as base training size
train_transform = presets.ssd.SSDDefaultTrainTransform(width, height)
val_transform = presets.ssd.SSDDefaultValTransform(width, height)
utils.random.seed(233) # fix seed in this tutorial
应用于训练图像的转换
train_image2, train_label2 = train_transform(train_image, train_label)
print('tensor shape:', train_image2.shape)
输出
tensor shape: (3, 512, 512)
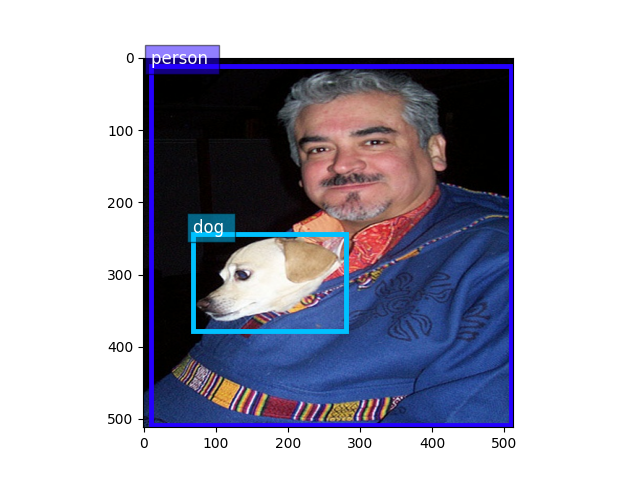
Tensor中的图像会失真,因为它们不再位于(0, 255)范围内。让我们将它们转换回去以便清晰查看。
train_image2 = train_image2.transpose(
(1, 2, 0)) * nd.array((0.229, 0.224, 0.225)) + nd.array((0.485, 0.456, 0.406))
train_image2 = (train_image2 * 255).clip(0, 255)
ax = viz.plot_bbox(train_image2.asnumpy(), train_label2[:, :4],
labels=train_label2[:, 4:5],
class_names=train_dataset.classes)
plt.show()
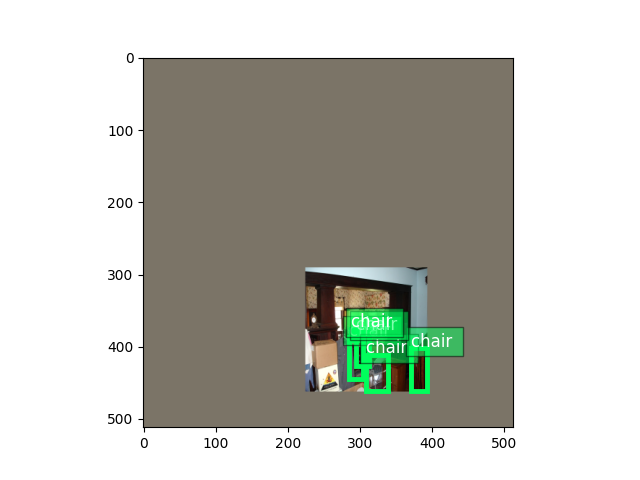
应用于验证图像的转换
val_image2, val_label2 = val_transform(val_image, val_label)
val_image2 = val_image2.transpose(
(1, 2, 0)) * nd.array((0.229, 0.224, 0.225)) + nd.array((0.485, 0.456, 0.406))
val_image2 = (val_image2 * 255).clip(0, 255)
ax = viz.plot_bbox(val_image2.clip(0, 255).asnumpy(), val_label2[:, :4],
labels=val_label2[:, 4:5],
class_names=train_dataset.classes)
plt.show()
训练中使用的转换包括随机扩展、随机裁剪、颜色失真、随机翻转等。相比之下,验证转换更简单,只使用了缩放和颜色归一化。
数据加载器¶
训练期间我们将多次迭代整个数据集。请记住,原始图像在馈送到神经网络之前必须转换为张量(MXNet使用BCHW格式)。此外,为了能够在mini-batch中运行,图像必须被调整到相同的形状。
一个便捷的数据加载器将非常方便我们应用不同的转换并将数据聚合到mini-batches中。
由于图像中的对象数量差异很大,因此标签大小也各不相同。因此,我们需要将这些标签填充到相同大小。为了解决这个问题,GluonCV提供了 gluoncv.data.batchify.Pad,它可以自动处理填充。此外, gluoncv.data.batchify.Stack 用于堆叠形状一致的NDArray。 gluoncv.data.batchify.Tuple 用于处理转换函数多个输出的不同行为。
from gluoncv.data.batchify import Tuple, Stack, Pad
from mxnet.gluon.data import DataLoader
batch_size = 2 # for tutorial, we use smaller batch-size
# you can make it larger(if your CPU has more cores) to accelerate data loading
num_workers = 0
# behavior of batchify_fn: stack images, and pad labels
batchify_fn = Tuple(Stack(), Pad(pad_val=-1))
train_loader = DataLoader(
train_dataset.transform(train_transform),
batch_size,
shuffle=True,
batchify_fn=batchify_fn,
last_batch='rollover',
num_workers=num_workers)
val_loader = DataLoader(
val_dataset.transform(val_transform),
batch_size,
shuffle=False,
batchify_fn=batchify_fn,
last_batch='keep',
num_workers=num_workers)
for ib, batch in enumerate(train_loader):
if ib > 3:
break
print('data:', batch[0].shape, 'label:', batch[1].shape)
输出
data: (2, 3, 512, 512) label: (2, 3, 6)
data: (2, 3, 512, 512) label: (2, 1, 6)
data: (2, 3, 512, 512) label: (2, 2, 6)
data: (2, 3, 512, 512) label: (2, 1, 6)
SSD网络¶
GluonCV的SSD实现是一个复合的Gluon HybridBlock(这意味着它可以导出为Symbol以便在C++、Scala和其他语言绑定中运行。我们将在未来的教程中介绍这种用法)。在结构上,SSD网络由基础特征提取网络、锚点生成器、类别预测器和边界框偏移预测器组成。
有关SSD检测器工作原理的更多详细信息,请参阅我们的入门教程 您也可以参考原始论文了解更多SSD背后的直觉。
Gluon模型库内置了许多SSD网络。您可以通过一行简单的代码加载您喜欢的网络
提示
为了避免在本教程中下载模型,我们将 pretrained_base=False。在实际应用中,我们通常希望通过设置 pretrained_base=True 来加载预训练的ImageNet模型。
from gluoncv import model_zoo
net = model_zoo.get_model('ssd_300_vgg16_atrous_voc', pretrained_base=False)
print(net)
输出
SSD(
(features): VGGAtrousExtractor(
(stages): HybridSequential(
(0): HybridSequential(
(0): Conv2D(None -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Activation(relu)
)
(1): HybridSequential(
(0): Conv2D(None -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Activation(relu)
)
(2): HybridSequential(
(0): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Activation(relu)
(4): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Activation(relu)
)
(3): HybridSequential(
(0): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Activation(relu)
(4): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Activation(relu)
)
(4): HybridSequential(
(0): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Activation(relu)
(4): Conv2D(None -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Activation(relu)
)
(5): HybridSequential(
(0): Conv2D(None -> 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(1): Activation(relu)
(2): Conv2D(None -> 1024, kernel_size=(1, 1), stride=(1, 1))
(3): Activation(relu)
)
)
(norm4): Normalize(
)
(extras): HybridSequential(
(0): HybridSequential(
(0): Conv2D(None -> 256, kernel_size=(1, 1), stride=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(3): Activation(relu)
)
(1): HybridSequential(
(0): Conv2D(None -> 128, kernel_size=(1, 1), stride=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(3): Activation(relu)
)
(2): HybridSequential(
(0): Conv2D(None -> 128, kernel_size=(1, 1), stride=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1))
(3): Activation(relu)
)
(3): HybridSequential(
(0): Conv2D(None -> 128, kernel_size=(1, 1), stride=(1, 1))
(1): Activation(relu)
(2): Conv2D(None -> 256, kernel_size=(3, 3), stride=(1, 1))
(3): Activation(relu)
)
)
)
(class_predictors): HybridSequential(
(0): ConvPredictor(
(predictor): Conv2D(None -> 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): ConvPredictor(
(predictor): Conv2D(None -> 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): ConvPredictor(
(predictor): Conv2D(None -> 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): ConvPredictor(
(predictor): Conv2D(None -> 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(4): ConvPredictor(
(predictor): Conv2D(None -> 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(5): ConvPredictor(
(predictor): Conv2D(None -> 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(box_predictors): HybridSequential(
(0): ConvPredictor(
(predictor): Conv2D(None -> 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): ConvPredictor(
(predictor): Conv2D(None -> 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): ConvPredictor(
(predictor): Conv2D(None -> 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): ConvPredictor(
(predictor): Conv2D(None -> 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(4): ConvPredictor(
(predictor): Conv2D(None -> 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(5): ConvPredictor(
(predictor): Conv2D(None -> 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(anchor_generators): HybridSequential(
(0): SSDAnchorGenerator(
)
(1): SSDAnchorGenerator(
)
(2): SSDAnchorGenerator(
)
(3): SSDAnchorGenerator(
)
(4): SSDAnchorGenerator(
)
(5): SSDAnchorGenerator(
)
)
(bbox_decoder): NormalizedBoxCenterDecoder(
)
(cls_decoder): MultiPerClassDecoder(
)
)
如前所述,SSD网络是一个HybridBlock。您可以使用输入调用它,如下所示:
SSD返回三个值,其中 cids 是类别标签, scores 是每个预测的置信度得分, bboxes 是相应边界框的绝对坐标。
SSD网络在训练模式下表现不同
在训练模式下,SSD返回三个中间值,其中 cls_preds 是Softmax之前的类别预测, box_preds 是与锚点一一对应的边界框偏移量,而 anchors 是对应锚点框的绝对坐标,由于训练图像使用相同尺寸的输入,这些坐标是固定的。
训练目标¶
与图像分类中使用的单个SoftmaxCrossEntropyLoss不同,SSD中使用的损失更复杂。不过不用担心,因为我们开箱即用地提供了这些模块。
为了加快训练速度,我们让CPU预先计算一些训练目标。当您的CPU性能强大并且您可以使用 -j num_workers 来利用多核CPU时,这一点特别有用。
如果我们向训练转换提供锚点,它将计算训练目标
from mxnet import gluon
train_transform = presets.ssd.SSDDefaultTrainTransform(width, height, anchors)
batchify_fn = Tuple(Stack(), Stack(), Stack())
train_loader = DataLoader(
train_dataset.transform(train_transform),
batch_size,
shuffle=True,
batchify_fn=batchify_fn,
last_batch='rollover',
num_workers=num_workers)
损失、Trainer和训练流程
from gluoncv.loss import SSDMultiBoxLoss
mbox_loss = SSDMultiBoxLoss()
trainer = gluon.Trainer(
net.collect_params(), 'sgd',
{'learning_rate': 0.001, 'wd': 0.0005, 'momentum': 0.9})
for ib, batch in enumerate(train_loader):
if ib > 0:
break
print('data:', batch[0].shape)
print('class targets:', batch[1].shape)
print('box targets:', batch[2].shape)
with autograd.record():
cls_pred, box_pred, anchors = net(batch[0])
sum_loss, cls_loss, box_loss = mbox_loss(
cls_pred, box_pred, batch[1], batch[2])
# some standard gluon training steps:
# autograd.backward(sum_loss)
# trainer.step(1)
输出
data: (2, 3, 512, 512)
class targets: (2, 24656)
box targets: (2, 24656, 4)
这次我们可以看到数据加载器实际上正在为我们返回训练目标。然后,很自然地就是一个带有Trainer的gluon训练循环,让它更新权重。
请查看完整的 训练脚本 以获取完整实现。