注意
点击 此处 下载完整的示例代码
4. 在 Pascal VOC 数据集上训练 FCN¶
这是一个使用 Gluon CV 工具包进行的语义分割教程,是一个循序渐进的示例。读者应具备深度学习基础知识,并熟悉 Gluon API。新用户可以先学习 A 60-minute Gluon Crash Course。您可以立即开始训练或深入探索。
立即开始训练¶
提示
您可以随意跳过本教程,因为训练脚本是独立的,可以直接启动。
示例训练命令
# First training on augmented set
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset pascal_aug --model fcn --backbone resnet50 --lr 0.001 --checkname mycheckpoint
# Finetuning on original set
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset pascal_voc --model fcn --backbone resnet50 --lr 0.0001 --checkname mycheckpoint --resume runs/pascal_aug/fcn/mycheckpoint/checkpoint.params
有关更多训练命令选项,请运行 python train.py -h 请查阅 模型动物园 以获取复现预训练模型的训练命令。
深入探索¶
import numpy as np
import mxnet as mx
from mxnet import gluon, autograd
import gluoncv
全卷积网络¶
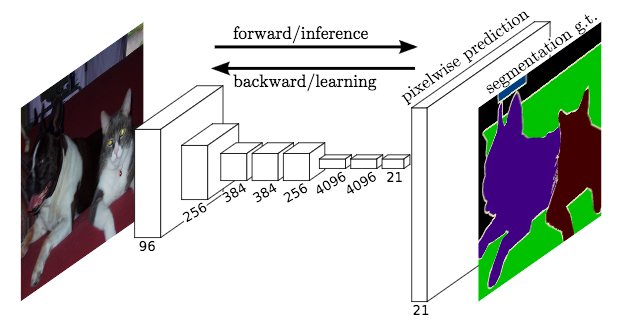
(图片来源:Long 等人)
当前最先进的语义分割方法通常基于全卷积网络 (FCN) [Long15]。全卷积网络的核心思想是它是“全卷积的”,这意味着它不包含任何全连接层。因此,网络可以接受任意大小的输入并进行密集的逐像素预测。基础/编码器网络通常在 ImageNet 上进行预训练,因为从多样化的图像集中学习到的特征包含丰富的上下文信息,这对语义分割是有益的。
模型扩张¶
在 ImageNet 上预训练的基础网络的适应性调整会导致空间分辨率损失,因为这些网络最初是为分类任务设计的。按照近期语义分割工作中的标准实现,我们对预训练网络的阶段 3 和阶段 4 应用扩张策略,生成步长为 8 的特征图(模型在 gluoncv.model_zoo.ResNetV1b 中提供)。扩张/空洞卷积的可视化(图片来源:conv_arithmetic)
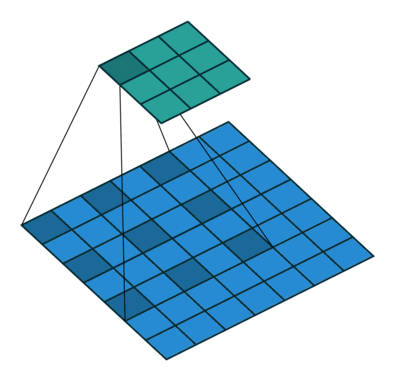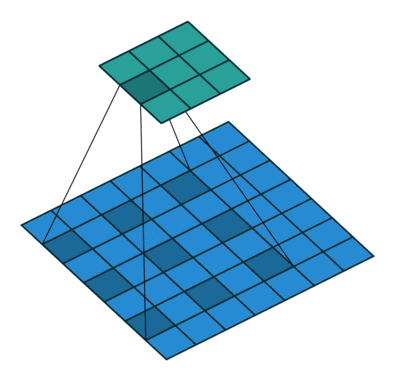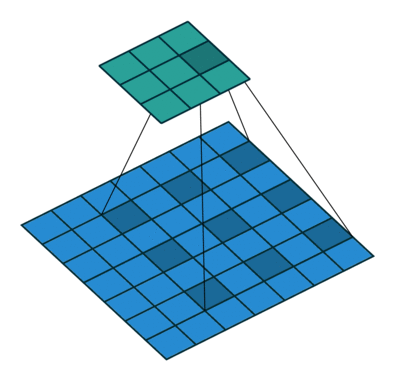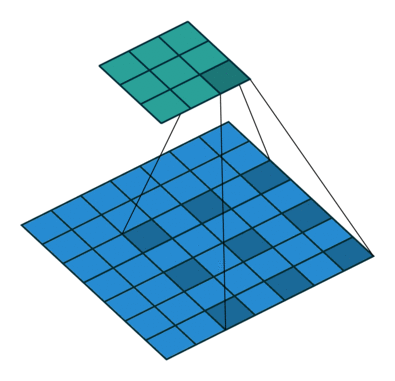
加载一个扩张 ResNet50 就像这样简单
pretrained_net = gluoncv.model_zoo.resnet50_v1b(pretrained=True)
输出
Downloading /root/.mxnet/models/resnet50_v1b-0ecdba34.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/resnet50_v1b-0ecdba34.zip...
0%| | 0/55344 [00:00<?, ?KB/s]
0%| | 101/55344 [00:00<01:09, 796.07KB/s]
1%| | 513/55344 [00:00<00:24, 2250.73KB/s]
4%|3 | 2177/55344 [00:00<00:07, 7236.37KB/s]
14%|#3 | 7726/55344 [00:00<00:02, 23667.96KB/s]
25%|##5 | 13938/55344 [00:00<00:01, 36251.20KB/s]
40%|###9 | 22106/55344 [00:00<00:00, 50722.84KB/s]
52%|#####1 | 28625/55344 [00:00<00:00, 55242.07KB/s]
66%|######6 | 36797/55344 [00:00<00:00, 61772.39KB/s]
81%|########1 | 45028/55344 [00:00<00:00, 67942.76KB/s]
95%|#########5| 52697/55344 [00:01<00:00, 70567.58KB/s]
100%|##########| 55344/55344 [00:01<00:00, 49603.53KB/s]
为方便起见,我们提供了一个用于语义分割的基础模型,它会自动加载预训练的扩张 ResNet gluoncv.model_zoo.segbase.SegBaseModel,并提供一个方便的方法 base_forward(input) 来获取阶段 3 和 4 的特征图
输出
Downloading /root/.mxnet/models/resnet50_v1s-25a187fa.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/resnet50_v1s-25a187fa.zip...
0%| | 0/57417 [00:00<?, ?KB/s]
6%|6 | 3660/57417 [00:00<00:01, 29403.33KB/s]
20%|## | 11642/57417 [00:00<00:00, 56341.89KB/s]
33%|###2 | 18905/57417 [00:00<00:00, 63389.25KB/s]
44%|####4 | 25430/57417 [00:00<00:00, 62913.29KB/s]
58%|#####7 | 33031/57417 [00:00<00:00, 67478.28KB/s]
70%|####### | 40306/57417 [00:00<00:00, 69230.31KB/s]
82%|########2 | 47291/57417 [00:00<00:00, 67710.66KB/s]
96%|#########6| 55134/57417 [00:00<00:00, 71001.66KB/s]
57418KB [00:00, 63212.84KB/s]
Shapes of c3 & c4 featuremaps are (1, 1024, 28, 28) (1, 2048, 28, 28)
FCN 模型¶
我们在基础网络之上构建了一个全卷积“头部”,FCNHead 的定义如下
class _FCNHead(HybridBlock):
def __init__(self, in_channels, channels, norm_layer, **kwargs):
super(_FCNHead, self).__init__()
with self.name_scope():
self.block = nn.HybridSequential()
inter_channels = in_channels // 4
with self.block.name_scope():
self.block.add(nn.Conv2D(in_channels=in_channels, channels=inter_channels,
kernel_size=3, padding=1))
self.block.add(norm_layer(in_channels=inter_channels))
self.block.add(nn.Activation('relu'))
self.block.add(nn.Dropout(0.1))
self.block.add(nn.Conv2D(in_channels=inter_channels, channels=channels,
kernel_size=1))
def hybrid_forward(self, F, x):
return self.block(x)
FCN 模型在 gluoncv.model_zoo.FCN 中提供。要获取使用 ResNet50 作为基础网络针对 Pascal VOC 数据集的 FCN 模型
model = gluoncv.model_zoo.get_fcn(dataset='pascal_voc', backbone='resnet50', pretrained=False)
print(model)
输出
FCN(
(conv1): HybridSequential(
(0): Conv2D(3 -> 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(2): Activation(relu)
(3): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(5): Activation(relu)
(6): Conv2D(64 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu): Activation(relu)
(maxpool): MaxPool2D(size=(3, 3), stride=(2, 2), padding=(1, 1), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(layer1): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(128 -> 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
(conv3): Conv2D(64 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(128 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(256 -> 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
(conv3): Conv2D(64 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(256 -> 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
(conv3): Conv2D(64 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu3): Activation(relu)
)
)
(layer2): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(256 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(256 -> 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(512 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(512 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
)
(3): BottleneckV1b(
(conv1): Conv2D(512 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
)
)
(layer3): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(512 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(512 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(3): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(4): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(5): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
)
(layer4): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(1024 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(conv3): Conv2D(512 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(1024 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(2048 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(conv3): Conv2D(512 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(2048 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(conv3): Conv2D(512 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(relu3): Activation(relu)
)
)
(head): _FCNHead(
(block): HybridSequential(
(0): Conv2D(2048 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(2): Activation(relu)
(3): Dropout(p = 0.1, axes=())
(4): Conv2D(512 -> 21, kernel_size=(1, 1), stride=(1, 1))
)
)
(auxlayer): _FCNHead(
(block): HybridSequential(
(0): Conv2D(1024 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
(3): Dropout(p = 0.1, axes=())
(4): Conv2D(256 -> 21, kernel_size=(1, 1), stride=(1, 1))
)
)
)
数据集和数据增强¶
用于颜色归一化的图像变换
from mxnet.gluon.data.vision import transforms
input_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([.485, .456, .406], [.229, .224, .225]),
])
我们在 gluoncv.data 中提供了语义分割数据集。例如,我们可以轻松获取 Pascal VOC 2012 数据集
trainset = gluoncv.data.VOCSegmentation(split='train', transform=input_transform)
print('Training images:', len(trainset))
# set batch_size = 2 for toy example
batch_size = 2
# Create Training Loader
train_data = gluon.data.DataLoader(
trainset, batch_size, shuffle=True, last_batch='rollover',
num_workers=batch_size)
输出
Training images: 2913
对于数据增强,我们遵循标准的数据增强流程,同步地变换输入图像和真实标签图。(注意,“nearest”模式的上采样应用于标签图以避免边界混乱。)我们首先将输入图像随机缩放 0.5 到 2.0 倍,然后旋转图像 -10 到 10 度,并在需要时通过填充来裁剪图像。最后应用随机高斯模糊。
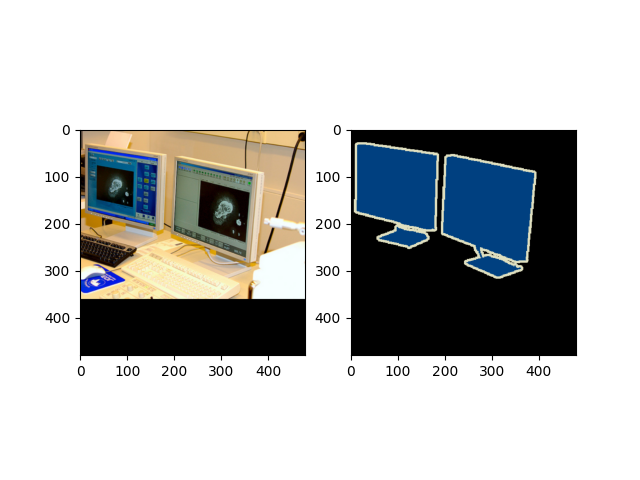
随机选取一个示例进行可视化
import random
from datetime import datetime
random.seed(datetime.now())
idx = random.randint(0, len(trainset))
img, mask = trainset[idx]
from gluoncv.utils.viz import get_color_pallete, DeNormalize
# get color pallete for visualize mask
mask = get_color_pallete(mask.asnumpy(), dataset='pascal_voc')
mask.save('mask.png')
# denormalize the image
img = DeNormalize([.485, .456, .406], [.229, .224, .225])(img)
img = np.transpose((img.asnumpy()*255).astype(np.uint8), (1, 2, 0))
绘制图像和掩码
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
# subplot 1 for img
fig = plt.figure()
fig.add_subplot(1,2,1)
plt.imshow(img)
# subplot 2 for the mask
mmask = mpimg.imread('mask.png')
fig.add_subplot(1,2,2)
plt.imshow(mmask)
# display
plt.show()
训练细节¶
训练损失
我们应用标准的逐像素 Softmax 交叉熵损失来训练 FCN。对于 Pascal VOC 数据集,我们忽略边界类别(编号 22)的损失。此外,在使用命令
--aux进行训练时,可以启用类似于 PSPNet [Zhao17] 中的辅助损失 (Auxiliary Loss)。这将在阶段 3 后创建一个额外的 FCN“头部”。
from gluoncv.loss import MixSoftmaxCrossEntropyLoss
criterion = MixSoftmaxCrossEntropyLoss(aux=True)
学习率和调度
我们对 FCN“头部”和基础网络使用不同的学习率。对于 FCN“头部”,我们使用基础学习率的 \(10\times\) 倍,因为这些层是从头开始学习的。我们对 FCN 训练使用多项式类型的学习率调度器,其实现包含在
gluoncv.utils.LRScheduler中。学习率由 \(lr = base_lr \times (1-iter)^{power}\) 给出
lr_scheduler = gluoncv.utils.LRScheduler('poly', base_lr=0.001,
nepochs=50, iters_per_epoch=len(train_data), power=0.9)
用于多 GPU 训练的数据并行,仅使用 CPU 进行演示
创建 SGD 优化器
kv = mx.kv.create('device')
optimizer = gluon.Trainer(model.module.collect_params(), 'sgd',
{'lr_scheduler': lr_scheduler,
'wd':0.0001,
'momentum': 0.9,
'multi_precision': True},
kvstore = kv)
训练循环¶
train_loss = 0.0
epoch = 0
for i, (data, target) in enumerate(train_data):
with autograd.record(True):
outputs = model(data)
losses = criterion(outputs, target)
mx.nd.waitall()
autograd.backward(losses)
optimizer.step(batch_size)
for loss in losses:
train_loss += loss.asnumpy()[0] / len(losses)
print('Epoch %d, batch %d, training loss %.3f'%(epoch, i, train_loss/(i+1)))
# just demo for 2 iters
if i > 1:
print('Terminated for this demo...')
break
输出
Epoch 0, batch 0, training loss 4.147
Epoch 0, batch 1, training loss 3.964
Epoch 0, batch 2, training loss 3.723
Terminated for this demo...
您可以立即开始训练。
参考文献¶
- Long15
Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “用于语义分割的全卷积网络。” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- Zhao17
Zhao, Hengshuang, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. “金字塔场景解析网络。” IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 2017.
脚本总运行时间:( 0 分钟 38.190 秒)