注意
点击 这里 下载完整示例代码
6. 在 Pascal VOC 数据集上重现 SoTA¶
这是一个使用 Gluon CV 工具包在 Pascal VOC 数据集上重现最先进(state-of-the-art,简称 SoTA)结果的语义分割教程。
立即开始训练¶
提示
您可以跳过本教程,因为训练脚本是独立的且可以直接运行。
训练 DeepLabV3 的示例命令
# First finetuning COCO dataset pretrained model on the augmented set
# If you would like to train from scratch on COCO, please see deeplab_resnet101_coco.sh
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset pascal_aug --model-zoo deeplab_resnet101_coco --aux --lr 0.001 --syncbn --ngpus 4 --checkname res101
# Finetuning on original set
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset pascal_voc --model deeplab --aux --backbone resnet101 --lr 0.0001 --syncbn --ngpus 4 --checkname res101 --resume runs/pascal_aug/deeplab/res101/checkpoint.params
有关更多训练命令选项,请运行 python train.py -h 请查阅模型库以获取重现预训练模型的训练命令。
import numpy as np
import mxnet as mx
from mxnet import gluon, autograd
import gluoncv
训练细节中的“陷阱”¶
由于复杂的训练细节,在 Pascal VOC 数据集上获得的最先进(state-of-the-art)结果 [Chen17] [Zhao17] 通常难以重现。在本教程中,我们将逐步讲解我们的最先进实现。
DeepLabV3 实现¶
我们在 Gluon-CV 中实现了最先进的 DeepLabV3 语义分割模型。空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,简称 ASPP)是 DeepLabV3 模型的关键部分,它构建在 FCN 之上。ASPP 通过使用不同空洞率的扩张卷积(dilated convolution)并结合一个具有全局感受野的全局池化分支,将具有不同感受野大小的多尺度特征进行组合。
ASPP 模块定义如下
class _ASPP(nn.HybridBlock):
def __init__(self, in_channels, atrous_rates, norm_layer, norm_kwargs):
super(_ASPP, self).__init__()
out_channels = 256
b0 = nn.HybridSequential()
with b0.name_scope():
b0.add(nn.Conv2D(in_channels=in_channels, channels=out_channels,
kernel_size=1, use_bias=False))
b0.add(norm_layer(in_channels=out_channels, **norm_kwargs))
b0.add(nn.Activation("relu"))
rate1, rate2, rate3 = tuple(atrous_rates)
b1 = _ASPPConv(in_channels, out_channels, rate1, norm_layer, norm_kwargs)
b2 = _ASPPConv(in_channels, out_channels, rate2, norm_layer, norm_kwargs)
b3 = _ASPPConv(in_channels, out_channels, rate3, norm_layer, norm_kwargs)
b4 = _AsppPooling(in_channels, out_channels, norm_layer=norm_layer,
norm_kwargs=norm_kwargs)
self.concurent = gluon.contrib.nn.HybridConcurrent(axis=1)
with self.concurent.name_scope():
self.concurent.add(b0)
self.concurent.add(b1)
self.concurent.add(b2)
self.concurent.add(b3)
self.concurent.add(b4)
self.project = nn.HybridSequential()
with self.project.name_scope():
self.project.add(nn.Conv2D(in_channels=5*out_channels, channels=out_channels,
kernel_size=1, use_bias=False))
self.project.add(norm_layer(in_channels=out_channels, **norm_kwargs))
self.project.add(nn.Activation("relu"))
self.project.add(nn.Dropout(0.5))
def hybrid_forward(self, F, x):
return self.project(self.concurent(x))
DeepLabV3 模型在 gluoncv.model_zoo.DeepLabV3 中提供。要获取使用 ResNet50 作为基础网络的 VOC 数据集 DeepLabV3 模型,可以使用
model = gluoncv.model_zoo.get_deeplab (dataset='pascal_voc', backbone='resnet50', pretrained=False)
print(model)
输出
DeepLabV3(
(conv1): HybridSequential(
(0): Conv2D(3 -> 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(2): Activation(relu)
(3): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(5): Activation(relu)
(6): Conv2D(64 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu): Activation(relu)
(maxpool): MaxPool2D(size=(3, 3), stride=(2, 2), padding=(1, 1), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(layer1): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(128 -> 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
(conv3): Conv2D(64 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(128 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(256 -> 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
(conv3): Conv2D(64 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(256 -> 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
(conv3): Conv2D(64 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu3): Activation(relu)
)
)
(layer2): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(256 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(256 -> 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(512 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(512 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
)
(3): BottleneckV1b(
(conv1): Conv2D(512 -> 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(conv3): Conv2D(128 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu3): Activation(relu)
)
)
(layer3): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(512 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(512 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(3): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(4): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
(5): BottleneckV1b(
(conv1): Conv2D(1024 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(conv3): Conv2D(256 -> 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=1024)
(relu3): Activation(relu)
)
)
(layer4): HybridSequential(
(0): BottleneckV1b(
(conv1): Conv2D(1024 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(conv3): Conv2D(512 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(relu3): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(1024 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
)
)
(1): BottleneckV1b(
(conv1): Conv2D(2048 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(conv3): Conv2D(512 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(relu3): Activation(relu)
)
(2): BottleneckV1b(
(conv1): Conv2D(2048 -> 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(conv3): Conv2D(512 -> 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(relu3): Activation(relu)
)
)
(head): _DeepLabHead(
(aspp): _ASPP(
(concurent): HybridConcurrent(
(0): HybridSequential(
(0): Conv2D(2048 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
)
(1): HybridSequential(
(0): Conv2D(2048 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(12, 12), dilation=(12, 12), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
)
(2): HybridSequential(
(0): Conv2D(2048 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(24, 24), dilation=(24, 24), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
)
(3): HybridSequential(
(0): Conv2D(2048 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(36, 36), dilation=(36, 36), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
)
(4): _AsppPooling(
(gap): HybridSequential(
(0): GlobalAvgPool2D(size=(1, 1), stride=(1, 1), padding=(0, 0), ceil_mode=True, global_pool=True, pool_type=avg, layout=NCHW)
(1): Conv2D(2048 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(3): Activation(relu)
)
)
)
(project): HybridSequential(
(0): Conv2D(1280 -> 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
(3): Dropout(p = 0.5, axes=())
)
)
(block): HybridSequential(
(0): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
(3): Dropout(p = 0.1, axes=())
(4): Conv2D(256 -> 21, kernel_size=(1, 1), stride=(1, 1))
)
)
(auxlayer): _FCNHead(
(block): HybridSequential(
(0): Conv2D(1024 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(2): Activation(relu)
(3): Dropout(p = 0.1, axes=())
(4): Conv2D(256 -> 21, kernel_size=(1, 1), stride=(1, 1))
)
)
)
COCO 预训练¶
COCO 数据集是一个大型实例分割数据集,包含 80 个类别和 12.7 万张训练图像。从 MS-COCO 数据集的训练集中,我们选取了包含与 PASCAL 数据集共享的 20 个类别且具有超过 1000 个标注像素的图像,得到 9.25 万张图像。所有其他类别都标记为背景。您可以使用以下命令轻松获取此数据集
# image transform for color normalization
from mxnet.gluon.data.vision import transforms
input_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([.485, .456, .406], [.229, .224, .225]),
])
# get the dataset
trainset = gluoncv.data.COCOSegmentation(split='train', transform=input_transform)
print('Training images:', len(trainset))
# set batch_size = 2 for toy example
batch_size = 2
# Create Training Loader
train_data = gluon.data.DataLoader(
trainset, batch_size, shuffle=True, last_batch='rollover',
num_workers=0)
输出
train set
loading annotations into memory...
Done (t=13.29s)
creating index...
index created!
Training images: 92516
绘制生成图像的示例
# Random pick one example for visualization:
import random
from datetime import datetime
random.seed(datetime.now())
idx = random.randint(0, len(trainset))
img, mask = trainset[idx]
from gluoncv.utils.viz import get_color_pallete, DeNormalize
# get color pallete for visualize mask
mask = get_color_pallete(mask.asnumpy(), dataset='coco')
mask.save('mask.png')
# denormalize the image
img = DeNormalize([.485, .456, .406], [.229, .224, .225])(img)
img = np.transpose((img.asnumpy()*255).astype(np.uint8), (1, 2, 0))
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
# subplot 1 for img
fig = plt.figure()
fig.add_subplot(1,2,1)
plt.imshow(img)
# subplot 2 for the mask
mmask = mpimg.imread('mask.png')
fig.add_subplot(1,2,2)
plt.imshow(mmask)
# display
plt.show()
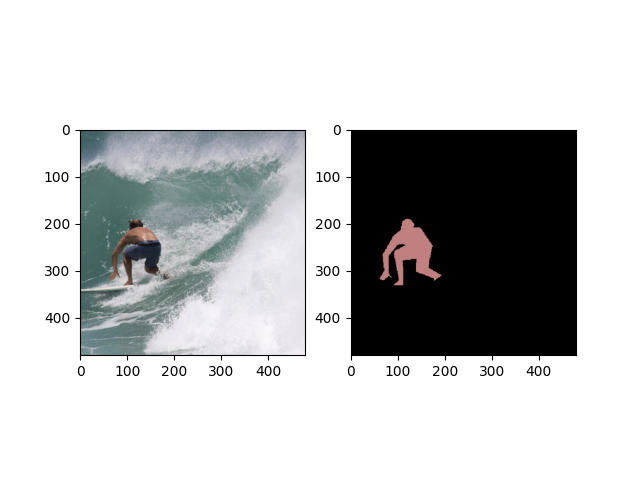
COCO 预训练的直接启动命令
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --dataset coco --model deeplab --aux --backbone resnet101 --lr 0.01 --syncbn --ngpus 4 --checkname res101 --epochs 30
您也可以通过获取预训练模型来跳过 COCO 预训练
from gluoncv import model_zoo
model_zoo.get_model('deeplab_resnet101_coco', pretrained=True)
Pascal VOC 和增强数据集¶
Pascal VOC 数据集 [Everingham10] 在训练集和验证集中共有 2,913 张图像。增强数据集 [Hariharan15] 有 10,582 张训练图像和 1449 张验证图像。我们首先在 Pascal 增强数据集上微调 COCO 预训练模型,然后再次在 Pascal VOC 数据集上微调以获得最佳性能。
学习率¶
我们对预训练的基础网络和没有预训练权重的 DeepLab 头部使用不同的学习率。我们将头部的学习率增大了 10 倍。使用了多项式余弦(poly-like cosine)学习率调度策略。学习率由 \(lr = base\_lr \times (1-iters/niters)^{power}\) 给出。有关更多详细信息,请查看 https://gluon-cv.mxnet.io/api/utils.html#gluoncv.utils.LRScheduler。
lr_scheduler = gluoncv.utils.LRScheduler(mode='poly', base_lr=0.01,
nepochs=30, iters_per_epoch=len(train_data), power=0.9)
我们首先使用 0.01 的基础学习率在 MS-COCO 数据集上进行预训练,然后在 Pascal 增强数据集和 Pascal VOC 原始数据集上微调时,分别将基础学习率除以 10 和 100。
您可以立即开始训练。
参考文献¶
- Chen17
Chen, Liang-Chieh, et al. “Rethinking atrous convolution for semantic image segmentation.” arXiv preprint arXiv:1706.05587 (2017).
- Zhao17
Zhao, Hengshuang, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. “Pyramid scene parsing network.” IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 2017.
- Everingham10
Everingham, Mark, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. “The pascal visual object classes (voc) challenge.” International journal of computer vision 88, no. 2 (2010): 303-338.
- Hariharan15
Hariharan, Bharath, Pablo Arbeláez, Ross Girshick, and Jitendra Malik. “Hypercolumns for object segmentation and fine-grained localization.” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 447-456. 2015.
脚本总运行时间: ( 0 分 23.867 秒)