注意
点击这里下载完整示例代码
4. 深入了解在 COCO 关键点上训练一个简单的姿态模型¶
在本教程中,我们将展示如何在 COCO 数据集上训练一个姿态估计模型1。
首先导入一些必要的模块。
from __future__ import division
import time, logging, os, math
import numpy as np
import mxnet as mx
from mxnet import gluon, nd
from mxnet import autograd as ag
from mxnet.gluon import nn
from mxnet.gluon.data.vision import transforms
from gluoncv.data import mscoco
from gluoncv.model_zoo import get_model
from gluoncv.utils import makedirs, LRScheduler
from gluoncv.data.transforms.presets.simple_pose import SimplePoseDefaultTrainTransform
from gluoncv.utils.metrics import HeatmapAccuracy
加载数据¶
我们可以使用 COCO Keypoints 数据集的官方 API 加载数据
train_dataset = mscoco.keypoints.COCOKeyPoints('~/.mxnet/datasets/coco',
splits=('person_keypoints_train2017'))
输出
loading annotations into memory...
Done (t=10.18s)
creating index...
index created!
数据集对象使我们能够检索包含人物的图像、人物的关键点以及元信息。
遵循原始论文,我们将输入大小调整为 (256, 192)。为了进行数据增强,我们随机缩放、旋转或翻转输入。最后,我们使用标准的 ImageNet 统计信息对其进行归一化。
COCO 关键点数据集包含一个人的 17 个关键点。每个关键点用三个数字 (x, y, v) 注释,其中 x 和 y 表示坐标,v 表示关键点是否可见。
对于每个关键点,我们生成一个以 (x, y) 坐标为中心的高斯核,并将其用作训练标签。这意味着模型在特征图上预测一个高斯分布。
transform_train = SimplePoseDefaultTrainTransform(num_joints=train_dataset.num_joints,
joint_pairs=train_dataset.joint_pairs,
image_size=(256, 192), heatmap_size=(64, 48),
scale_factor=0.30, rotation_factor=40, random_flip=True)
现在我们可以使用数据集和变换定义我们的数据加载器。我们将在训练循环中迭代 train_data。
batch_size = 32
train_data = gluon.data.DataLoader(
train_dataset.transform(transform_train),
batch_size=batch_size, shuffle=True, last_batch='discard', num_workers=0)
反卷积层¶
反卷积层会放大输入的特征图尺寸,因此可以将其视为对输入特征图进行上采样的层。
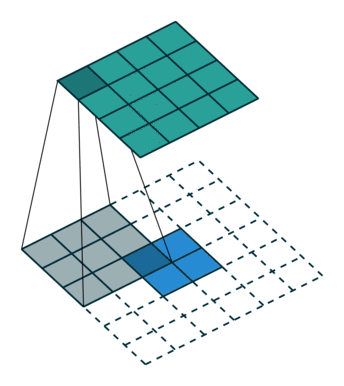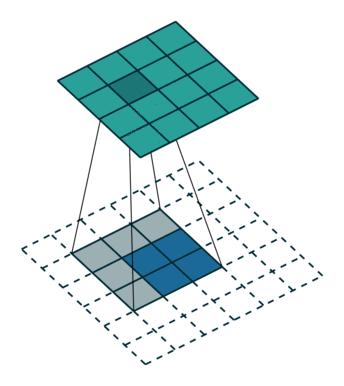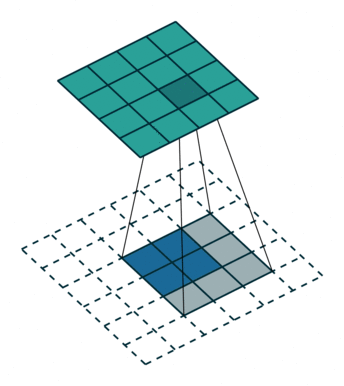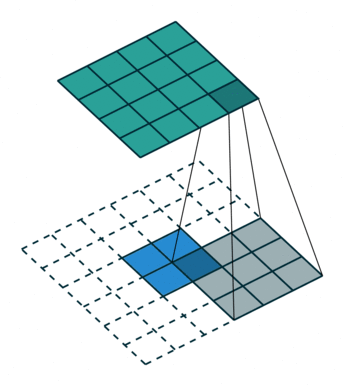
上图中,蓝色图是输入特征图,青色图是输出。
在 ResNet 模型中,最后一个特征图将其高度和宽度缩小到输入的 1/32。对于热力图预测来说可能太小。然而,如果跟随几个反卷积层,特征图可以具有更大的尺寸,从而更容易进行预测。
模型定义¶
一个简单的姿态模型由一个 ResNet 主体和几个反卷积层组成。其最后一层是一个卷积层,用于预测每个关键点的一个热力图。
让我们看看 GluonCV 模型库中最小的一个,它使用 ResNet18 作为其基础模型。
我们加载 ResNet18 层的预训练参数,并初始化反卷积层和最终的卷积层。
输出
Downloading /root/.mxnet/models/resnet18_v1b-2d9d980c.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/resnet18_v1b-2d9d980c.zip...
0%| | 0/42432 [00:00<?, ?KB/s]
0%| | 101/42432 [00:00<00:50, 846.11KB/s]
1%|1 | 509/42432 [00:00<00:17, 2357.30KB/s]
5%|5 | 2184/42432 [00:00<00:05, 7637.95KB/s]
20%|#9 | 8294/42432 [00:00<00:01, 26447.47KB/s]
37%|###7 | 15769/42432 [00:00<00:00, 42603.71KB/s]
53%|#####2 | 22424/42432 [00:00<00:00, 50332.53KB/s]
74%|#######3 | 31349/42432 [00:00<00:00, 62624.99KB/s]
93%|#########2| 39433/42432 [00:00<00:00, 68287.19KB/s]
42433KB [00:00, 47641.70KB/s]
我们可以查看模型的摘要
输出
--------------------------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================================
Input (1, 3, 256, 192) 0
Conv2D-1 (1, 64, 128, 96) 9408
BatchNormCudnnOff-2 (1, 64, 128, 96) 256
Activation-3 (1, 64, 128, 96) 0
MaxPool2D-4 (1, 64, 64, 48) 0
Conv2D-5 (1, 64, 64, 48) 36864
BatchNormCudnnOff-6 (1, 64, 64, 48) 256
Activation-7 (1, 64, 64, 48) 0
Conv2D-8 (1, 64, 64, 48) 36864
BatchNormCudnnOff-9 (1, 64, 64, 48) 256
Activation-10 (1, 64, 64, 48) 0
BasicBlockV1b-11 (1, 64, 64, 48) 0
Conv2D-12 (1, 64, 64, 48) 36864
BatchNormCudnnOff-13 (1, 64, 64, 48) 256
Activation-14 (1, 64, 64, 48) 0
Conv2D-15 (1, 64, 64, 48) 36864
BatchNormCudnnOff-16 (1, 64, 64, 48) 256
Activation-17 (1, 64, 64, 48) 0
BasicBlockV1b-18 (1, 64, 64, 48) 0
Conv2D-19 (1, 128, 32, 24) 73728
BatchNormCudnnOff-20 (1, 128, 32, 24) 512
Activation-21 (1, 128, 32, 24) 0
Conv2D-22 (1, 128, 32, 24) 147456
BatchNormCudnnOff-23 (1, 128, 32, 24) 512
Conv2D-24 (1, 128, 32, 24) 8192
BatchNormCudnnOff-25 (1, 128, 32, 24) 512
Activation-26 (1, 128, 32, 24) 0
BasicBlockV1b-27 (1, 128, 32, 24) 0
Conv2D-28 (1, 128, 32, 24) 147456
BatchNormCudnnOff-29 (1, 128, 32, 24) 512
Activation-30 (1, 128, 32, 24) 0
Conv2D-31 (1, 128, 32, 24) 147456
BatchNormCudnnOff-32 (1, 128, 32, 24) 512
Activation-33 (1, 128, 32, 24) 0
BasicBlockV1b-34 (1, 128, 32, 24) 0
Conv2D-35 (1, 256, 16, 12) 294912
BatchNormCudnnOff-36 (1, 256, 16, 12) 1024
Activation-37 (1, 256, 16, 12) 0
Conv2D-38 (1, 256, 16, 12) 589824
BatchNormCudnnOff-39 (1, 256, 16, 12) 1024
Conv2D-40 (1, 256, 16, 12) 32768
BatchNormCudnnOff-41 (1, 256, 16, 12) 1024
Activation-42 (1, 256, 16, 12) 0
BasicBlockV1b-43 (1, 256, 16, 12) 0
Conv2D-44 (1, 256, 16, 12) 589824
BatchNormCudnnOff-45 (1, 256, 16, 12) 1024
Activation-46 (1, 256, 16, 12) 0
Conv2D-47 (1, 256, 16, 12) 589824
BatchNormCudnnOff-48 (1, 256, 16, 12) 1024
Activation-49 (1, 256, 16, 12) 0
BasicBlockV1b-50 (1, 256, 16, 12) 0
Conv2D-51 (1, 512, 8, 6) 1179648
BatchNormCudnnOff-52 (1, 512, 8, 6) 2048
Activation-53 (1, 512, 8, 6) 0
Conv2D-54 (1, 512, 8, 6) 2359296
BatchNormCudnnOff-55 (1, 512, 8, 6) 2048
Conv2D-56 (1, 512, 8, 6) 131072
BatchNormCudnnOff-57 (1, 512, 8, 6) 2048
Activation-58 (1, 512, 8, 6) 0
BasicBlockV1b-59 (1, 512, 8, 6) 0
Conv2D-60 (1, 512, 8, 6) 2359296
BatchNormCudnnOff-61 (1, 512, 8, 6) 2048
Activation-62 (1, 512, 8, 6) 0
Conv2D-63 (1, 512, 8, 6) 2359296
BatchNormCudnnOff-64 (1, 512, 8, 6) 2048
Activation-65 (1, 512, 8, 6) 0
BasicBlockV1b-66 (1, 512, 8, 6) 0
Conv2DTranspose-67 (1, 256, 16, 12) 2097152
BatchNormCudnnOff-68 (1, 256, 16, 12) 1024
Activation-69 (1, 256, 16, 12) 0
Conv2DTranspose-70 (1, 256, 32, 24) 1048576
BatchNormCudnnOff-71 (1, 256, 32, 24) 1024
Activation-72 (1, 256, 32, 24) 0
Conv2DTranspose-73 (1, 256, 64, 48) 1048576
BatchNormCudnnOff-74 (1, 256, 64, 48) 1024
Activation-75 (1, 256, 64, 48) 0
Conv2D-76 (1, 17, 64, 48) 4369
SimplePoseResNet-77 (1, 17, 64, 48) 0
================================================================================
Parameters in forward computation graph, duplicate included
Total params: 15387857
Trainable params: 15376721
Non-trainable params: 11136
Shared params in forward computation graph: 0
Unique parameters in model: 15387857
--------------------------------------------------------------------------------
注意
正如这些问题 [2],[3] 中所报告的,cuDNN 的 Batch Normalization 实现对模型训练有负面影响。
由于观察到类似的行为,我们实现了一个 BatchNormCudnnOff 层作为临时解决方案。该层不调用 cuDNN 的 Batch Normalization 层,因此能给出更好的结果。
训练设置¶
接下来,我们可以设置训练所需的一切。
损失
我们在预测的热力图上应用加权
L2Loss,如果关键点可见,权重为 1,否则为 0。
L = gluon.loss.L2Loss()
学习率调整和优化器
我们使用初始学习率为 0.001,并在第 90 和 120 个 epoch 将其除以 10。
num_training_samples = len(train_dataset)
num_batches = num_training_samples // batch_size
lr_scheduler = LRScheduler(mode='step', base_lr=0.001,
iters_per_epoch=num_batches, nepochs=140,
step_epoch=(90, 120), step_factor=0.1)
对于此模型,我们使用 adam 作为优化器。
trainer = gluon.Trainer(net.collect_params(), 'adam', {'lr_scheduler': lr_scheduler})
指标
该模型的指标称为热力图精度,即它比较预测和真实值的关键点热力图,并检查高斯分布的中心是否在一定距离内。
训练循环¶
既然我们已经准备好所有必要的模块,现在可以将它们组合起来开始训练。
net.hybridize(static_alloc=True, static_shape=True)
for epoch in range(1):
metric.reset()
for i, batch in enumerate(train_data):
if i > 0:
break
data = gluon.utils.split_and_load(batch[0], ctx_list=[context], batch_axis=0)
label = gluon.utils.split_and_load(batch[1], ctx_list=[context], batch_axis=0)
weight = gluon.utils.split_and_load(batch[2], ctx_list=[context], batch_axis=0)
with ag.record():
outputs = [net(X) for X in data]
loss = [L(yhat, y, w) for yhat, y, w in zip(outputs, label, weight)]
for l in loss:
l.backward()
trainer.step(batch_size)
metric.update(label, outputs)
break
由于资源限制,本教程中我们只训练一个批次模型。
请查看完整的训练脚本以复现我们的结果。
参考文献¶
- 1
Xiao, Bin, Haiping Wu, and Yichen Wei. “Simple baselines for human pose estimation and tracking.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
- 2
https://github.com/Microsoft/human-pose-estimation.pytorch/issues/48
- 3
脚本总运行时间: ( 1 分 43.931 秒)