注意
点击此处下载完整示例代码
准备 ImageNet 数据集¶
ImageNet 项目包含数百万张图像和数千种用于图像分类的对象。它在研究社区中被广泛用于评估最先进的模型。

该数据集有多个版本。常用的图像分类版本是 ILSVRC 2012。本教程将详细介绍为 GluonCV 准备该数据集的步骤。
注意
您至少需要 300 GB 的磁盘空间来下载和提取数据集。由于速度更快,推荐使用 SSD(固态硬盘)而非 HDD。
下载¶
首先,访问下载页面(您可能需要注册一个账户),找到 ILSVRC2012 的页面。然后,找到并下载以下两个文件
文件名 |
大小 |
|---|---|
ILSVRC2012_img_train.tar |
138 GB |
ILSVRC2012_img_val.tar |
6.3 GB |
设置¶
首先,请下载帮助脚本 imagenet.py 和验证图像信息文件 imagenet_val_maps.pklz。请确保将它们放在同一个目录中。
假设 tar 文件保存在文件夹 ~/ILSVRC2012 中。我们可以使用以下命令自动准备数据集。
python imagenet.py --download-dir ~/ILSVRC2012
注意
提取图像可能需要一些时间。例如,在带有 EBS 的 AWS EC2 实例上大约需要 30 分钟。
默认情况下,imagenet.py 会将图像提取到 ~/.mxnet/datasets/imagenet。您可以通过设置 --target-dir 指定不同的目标文件夹。
使用 GluonCV 读取¶
准备好的数据集可以直接使用工具类 gluoncv.data.ImageNet 加载。下面是一个示例,每次随机读取 128 张图像并执行随机缩放和裁剪。
from gluoncv.data import ImageNet
from mxnet.gluon.data import DataLoader
from mxnet.gluon.data.vision import transforms
train_trans = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ToTensor()
])
# You need to specify ``root`` for ImageNet if you extracted the images into
# a different folder
train_data = DataLoader(
ImageNet(train=True).transform_first(train_trans),
batch_size=128, shuffle=True)
输出结果
(128, 3, 224, 224) (128,)
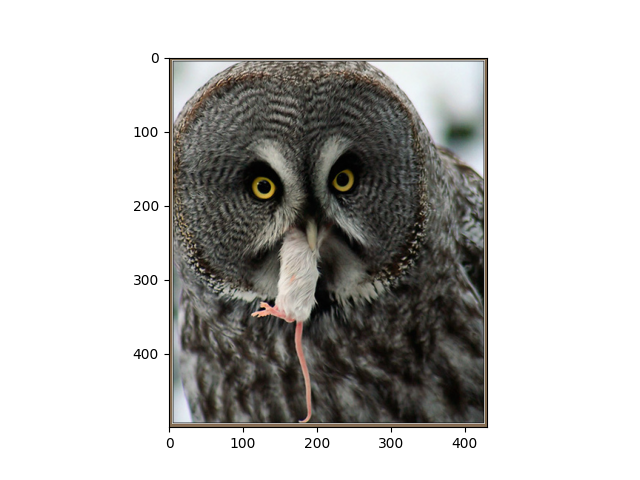
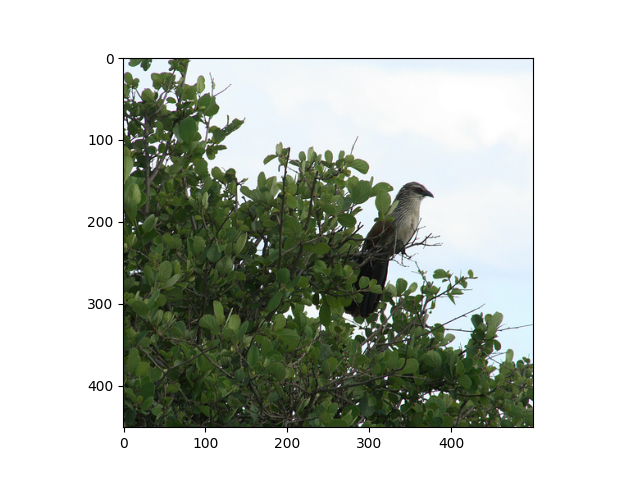
绘制一些验证图像
from gluoncv.utils import viz
val_dataset = ImageNet(train=False)
viz.plot_image(val_dataset[1234][0]) # index 0 is image, 1 is label
viz.plot_image(val_dataset[4567][0])
脚本总运行时间: ( 3 分钟 40.158 秒)