注意
点击这里下载完整示例代码
3. 从您的网络摄像头估计姿态¶
本文将演示如何从您的网络摄像头视频流中估计人物姿态。
首先,导入必要的模块。
from __future__ import division
import argparse, time, logging, os, math, tqdm, cv2
import numpy as np
import mxnet as mx
from mxnet import gluon, nd, image
from mxnet.gluon.data.vision import transforms
import matplotlib.pyplot as plt
import gluoncv as gcv
from gluoncv import data
from gluoncv.data import mscoco
from gluoncv.model_zoo import get_model
from gluoncv.data.transforms.pose import detector_to_simple_pose, heatmap_to_coord
from gluoncv.utils.viz import cv_plot_image, cv_plot_keypoints
加载模型和网络摄像头¶
在本教程中,我们将网络摄像头的帧输入到检测器中,然后估计帧中每个检测到的人物姿态。
对于检测器,我们使用 ssd_512_mobilenet1.0_coco,因为它足够快速和准确。
ctx = mx.cpu()
detector_name = "ssd_512_mobilenet1.0_coco"
detector = get_model(detector_name, pretrained=True, ctx=ctx)
预训练模型试图检测图像中所有 80 类物体,但在姿态估计中,我们只对一类物体感兴趣:人物。
为了加快检测器速度,我们可以重置预测头,使其只包含我们需要的类别。
detector.reset_class(classes=['person'], reuse_weights={'person':'person'})
detector.hybridize()
接下来对于估计器,我们选择 simple_pose_resnet18_v1b,因为它轻量级。
默认的 simple_pose_resnet18_v1b 模型使用 256x192 的输入尺寸进行训练。我们还提供了一个可选的 simple_pose_resnet18_v1b 模型,其输入尺寸为 128x96。后一个模型速度更快,这意味着更流畅的网络摄像头演示。请记住,我们可以通过将其 shasum 传递给 pretrained 来加载一个可选的预训练模型。
estimators = get_model('simple_pose_resnet18_v1b', pretrained='ccd24037', ctx=ctx)
estimators.hybridize()
使用 OpenCV,我们可以轻松地从网络摄像头获取帧。
cap = cv2.VideoCapture(0)
time.sleep(1) ### letting the camera autofocus
注意
在代码中,我们在 CPU 上运行演示,如果您的机器有 GPU,您可以尝试更重、更准确的预训练检测器和估计器。
有关模型选择列表,请参考我们的检测和姿态估计模型库页面。
估计循环¶
对于每一帧,我们执行以下步骤
加载网络摄像头帧
预处理图像
检测图像中的人物
后处理检测到的人物
估计每个人的姿态
绘制结果
axes = None
num_frames = 100
for i in range(num_frames):
ret, frame = cap.read()
frame = mx.nd.array(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)).astype('uint8')
x, frame = gcv.data.transforms.presets.ssd.transform_test(frame, short=512, max_size=350)
x = x.as_in_context(ctx)
class_IDs, scores, bounding_boxs = detector(x)
pose_input, upscale_bbox = detector_to_simple_pose(frame, class_IDs, scores, bounding_boxs,
output_shape=(128, 96), ctx=ctx)
if len(upscale_bbox) > 0:
predicted_heatmap = estimators(pose_input)
pred_coords, confidence = heatmap_to_coord(predicted_heatmap, upscale_bbox)
img = cv_plot_keypoints(frame, pred_coords, confidence, class_IDs, bounding_boxs, scores,
box_thresh=0.5, keypoint_thresh=0.2)
cv_plot_image(img)
cv2.waitKey(1)
在退出前释放网络摄像头
cap.release()
结果¶
下载脚本运行演示
运行脚本
python cam_demo.py --num-frames 100
如果一切顺利,您应该能看到您的姿态被检测到!
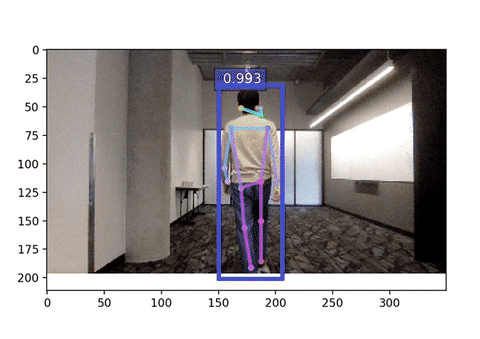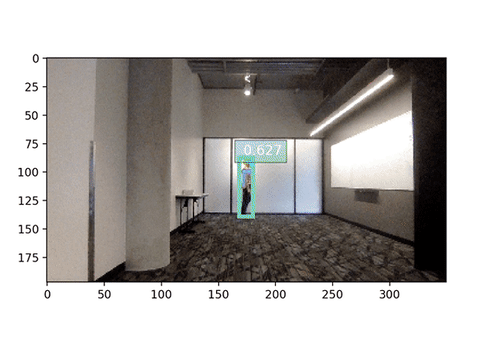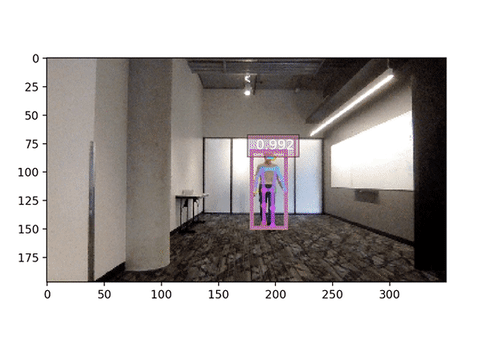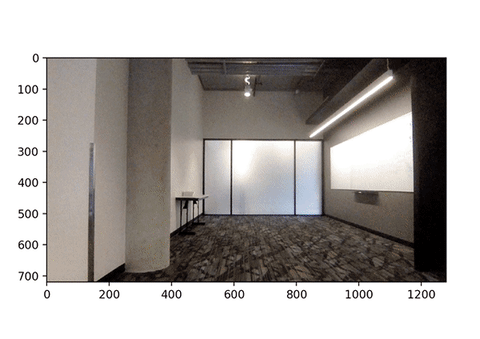
输入尺寸显著影响推理速度。下方是输入尺寸为 256x192 的网络摄像头演示,比较一下帧率!

脚本总运行时间: ( 0 分 0.000 秒)