注意
点击此处下载完整的示例代码
准备 HMDB51 数据集¶
HMDB51 是一个行为识别数据集,从各种来源收集,大部分来自电影,一小部分来自公共数据库,如 Prelinger Archive、YouTube 和 Google Videos。该数据集包含 6,766 个片段,分为 51 个行为类别,每个类别至少包含 100 个片段。本教程将逐步介绍为 GluonCV 准备此数据集的步骤。

设置¶
我们需要 HMDB51 的以下两个文件:数据集和官方训练/测试分割。
文件名 |
大小 |
|---|---|
hmdb51_org.rar |
2.1 GB |
test_train_splits.rar |
200 KB |
下载和解压这些文件的最简单方法是下载辅助脚本hmdb51.py并运行以下命令
python hmdb51.py
此脚本将帮助您下载数据集、从压缩文件解压数据、将视频解码为帧,并为您生成训练文件。所有文件默认将存储在~/.mxnet/datasets/hmdb51。如果您想使用更多 worker 来加速,请将--num-worker指定为更大的数字。
注意
您至少需要 60 GB 的磁盘空间来下载和提取数据集。由于速度更快,SSD(固态硬盘)优于 HDD。
您可能需要使用sudo apt install unrar安装unrar。
您可能需要使用pip install rarfile Cython mmcv安装rarfile、Cython、mmcv。
数据准备过程可能需要一些时间。准备数据集的总时间取决于您的互联网速度和磁盘性能。例如,在带有 EBS 的 AWS EC2 实例上大约需要 30 分钟。
使用 GluonCV 读取¶
准备好的数据集可以直接使用工具类gluoncv.data.HMDB51加载。在本教程中,我们提供三个示例来从数据集中读取数据,(1) 每视频加载一帧;(2) 每视频加载一个片段,该片段包含五帧连续帧;(3) 每视频均匀加载三个片段,每个片段包含 12 帧。
我们首先展示一个示例,每次随机读取 25 个视频,每视频随机选择一帧并执行中心裁剪。
from gluoncv.data import HMDB51
from mxnet.gluon.data import DataLoader
from mxnet.gluon.data.vision import transforms
from gluoncv.data.transforms import video
transform_train = transforms.Compose([
video.VideoCenterCrop(size=224),
video.VideoToTensor()
])
# Default location of the data is stored on ~/.mxnet/datasets/hmdb51.
# You need to specify ``setting`` and ``root`` for HMDB51 if you decoded the video frames into a different folder.
train_dataset = HMDB51(train=True, transform=transform_train)
train_data = DataLoader(train_dataset, batch_size=25, shuffle=True)
我们可以看到加载的数据形状如下。extra表示我们是否从视频中选择多个裁剪或多个片段。在这里,我们每视频只选择一帧,因此extra维度是 1。
输出
Video frame size (batch, extra, channel, height, width): (25, 1, 3, 224, 224)
Video label: (25,)
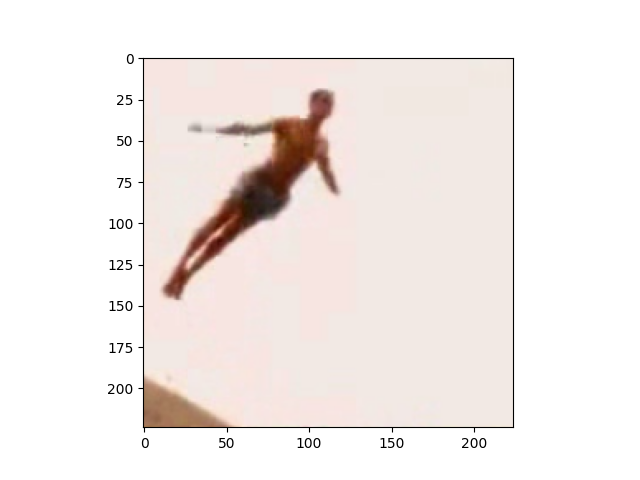
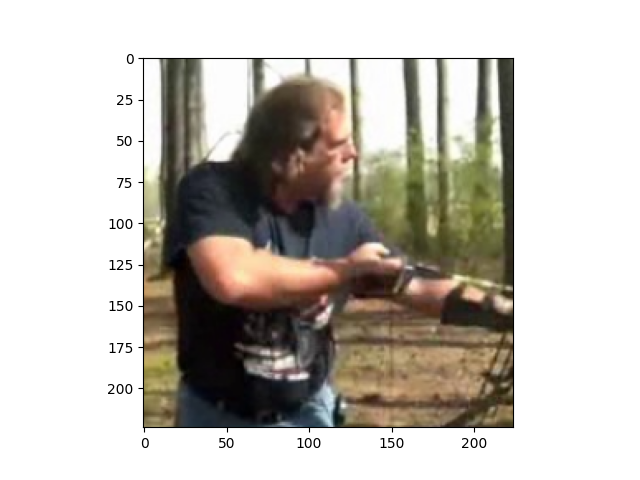
让我们绘制几个训练样本。索引 0 是图像,1 是标签。
from gluoncv.utils import viz
viz.plot_image(train_dataset[500][0].squeeze().transpose((1,2,0))*255.0) # dive
viz.plot_image(train_dataset[2500][0].squeeze().transpose((1,2,0))*255.0) # shoot_bow
这是第二个示例,每次随机读取 25 个视频,每视频随机选择一个片段并执行中心裁剪。一个片段可以包含 N 个连续帧,例如 N=5。
train_dataset = HMDB51(train=True, new_length=5, transform=transform_train)
train_data = DataLoader(train_dataset, batch_size=25, shuffle=True)
我们可以看到加载的数据形状如下。现在我们有了另一个depth维度,它表示每个片段中有多少帧(也称为时间维度)。
输出
Video frame size (batch, extra, channel, depth, height, width): (25, 1, 3, 5, 224, 224)
Video label: (25,)
让我们绘制一个包含 5 个连续视频帧的训练样本。索引 0 是图像,1 是标签。
from matplotlib import pyplot as plt
# subplot 1 for video frame 1
fig = plt.figure()
fig.add_subplot(1,5,1)
frame1 = train_dataset[500][0][0,:,0,:,:].transpose((1,2,0)).asnumpy()*255.0
plt.imshow(frame1.astype('uint8'))
# subplot 2 for video frame 2
fig.add_subplot(1,5,2)
frame2 = train_dataset[500][0][0,:,1,:,:].transpose((1,2,0)).asnumpy()*255.0
plt.imshow(frame2.astype('uint8'))
# subplot 3 for video frame 3
fig.add_subplot(1,5,3)
frame3 = train_dataset[500][0][0,:,2,:,:].transpose((1,2,0)).asnumpy()*255.0
plt.imshow(frame3.astype('uint8'))
# subplot 4 for video frame 4
fig.add_subplot(1,5,4)
frame4 = train_dataset[500][0][0,:,3,:,:].transpose((1,2,0)).asnumpy()*255.0
plt.imshow(frame4.astype('uint8'))
# subplot 5 for video frame 5
fig.add_subplot(1,5,5)
frame5 = train_dataset[500][0][0,:,4,:,:].transpose((1,2,0)).asnumpy()*255.0
plt.imshow(frame5.astype('uint8'))
# display
plt.show()

最后一个示例是,我们每次随机读取 25 个视频,每视频均匀选择三个片段并执行中心裁剪。一个片段包含 12 个连续帧。
train_dataset = HMDB51(train=True, new_length=12, num_segments=3, transform=transform_train)
train_data = DataLoader(train_dataset, batch_size=25, shuffle=True)
我们可以看到加载的数据形状如下。现在extra维度是 3,这表示每个视频我们有三个片段。
输出
Video frame size (batch, extra, channel, depth, height, width): (25, 3, 3, 12, 224, 224)
Video label: (25,)
有许多不同的方法来加载数据。我们建议用户阅读参数列表以获取更多信息。
脚本总运行时间: ( 0 分钟 16.513 秒)