注意
点击此处下载完整的示例代码
03. 在 KITTI 数据集上训练 Monodepth2¶
这是一篇使用 Gluon CV 工具包在 KITTI 数据集上训练 MonoDepth2 的教程。读者应具备深度学习基础知识,并熟悉 Gluon API。新用户可以先阅读60 分钟 Gluon 速成课程。您可以立即开始训练或深入探索。
立即开始训练¶
提示
请随意跳过教程,因为训练脚本是完整的,可以直接运行。
单目+双目模式训练命令
python train.py --model_zoo monodepth2_resnet18_kitti_mono_stereo_640x192 --model_zoo_pose monodepth2_resnet18_posenet_kitti_mono_stereo_640x192 --pretrained_base --frame_ids 0 -1 1 --use_stereo --log_dir ./tmp/mono_stereo/ --png --gpu 0 --batch_size 8
单目模式训练命令
python train.py --model_zoo monodepth2_resnet18_kitti_mono_640x192 --model_zoo_pose monodepth2_resnet18_posenet_kitti_mono_640x192 --pretrained_base --log_dir ./tmp/mono/ --png --gpu 0 --batch_size 12
双目模式训练命令
python train.py --model_zoo monodepth2_resnet18_kitti_stereo_640x192 --pretrained_base --split eigen_full --frame_ids 0 --use_stereo --log_dir ./tmp/stereo/ --png --gpu 0 --batch_size 12
更多训练命令选项,请运行 python train.py -h。请查看模型动物园,以获取重现预训练模型的训练命令。
深入探索¶
import numpy as np
import mxnet as mx
from mxnet import gluon, autograd
import gluoncv
深入研究自监督单目深度预测¶
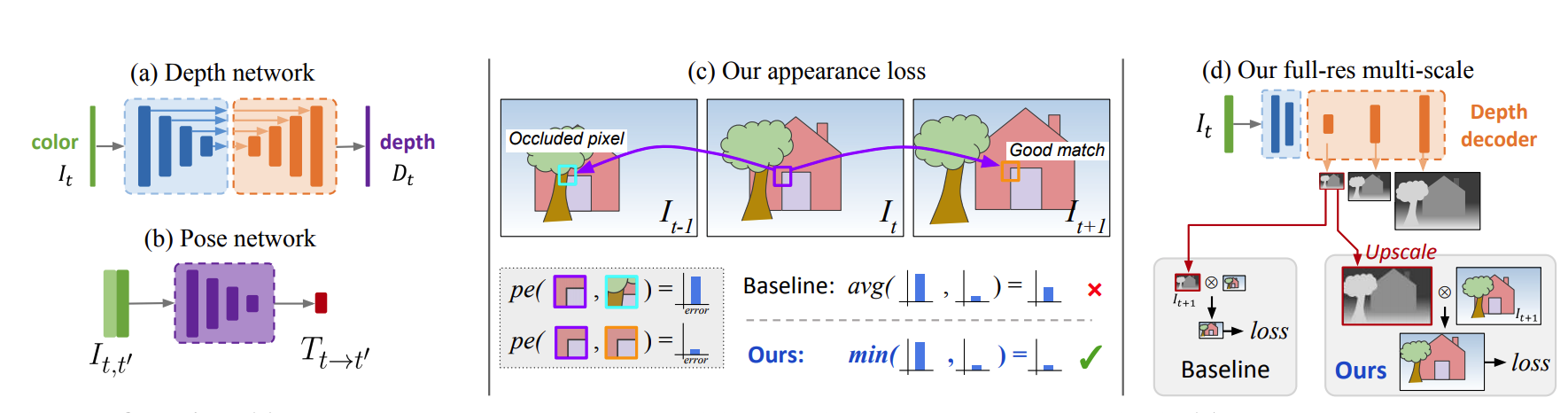
(图片来源:Godard 等人)
自监督单目深度估计(Monodepth2)[Godard19] 构建了一个简单的深度模型,并通过利用空间几何约束以自监督的方式进行训练。Monodepth2 的关键思想是它构建了一种新颖的重投影损失,包括 (1) 用于稳健处理遮挡的最小重投影损失,(2) 减少视觉伪影的全分辨率多尺度采样方法,以及 (3) 用于忽略违反相机运动假设的训练像素的自动遮罩损失。
Monodepth2 模型¶
Monodepth2 使用了一个简单的 U-Net 架构,它结合了不同感受野大小的多尺度特征。它将特征图汇聚成不同大小,然后在上采样后进行拼接。有两个解码器分别用于深度估计和相机姿态估计。
编码器模块是 ResNet,它接受单张 RGB 图像作为深度模型的输入。对于姿态模型,姿态编码器经过修改,接受一对帧(即六个通道)作为输入。因此,姿态编码器第一层的卷积权重形状为 6×64×3×3,而不是 ResNet 默认的 3×64×3×3。在使用姿态编码器的预训练权重时,第一个预训练的滤波器张量沿通道维度复制以形成形状为 6 × 64 × 3 × 3 的滤波器。这个新扩展滤波器中的所有权重都除以 2,以使卷积的输出与原始单图像 ResNet 的输出在数值范围上相同。
编码器定义如下:
class ResnetEncoder(nn.HybridBlock):
def __init__(self, backbone, pretrained, num_input_images=1,
root=os.path.join(os.path.expanduser('~'), '.mxnet/models'),
ctx=cpu(), **kwargs):
super(ResnetEncoder, self).__init__()
self.num_ch_enc = np.array([64, 64, 128, 256, 512])
resnets = {'resnet18': resnet18_v1b,
'resnet34': resnet34_v1b,
'resnet50': resnet50_v1s,
'resnet101': resnet101_v1s,
'resnet152': resnet152_v1s}
num_layers = {'resnet18': 18,
'resnet34': 34,
'resnet50': 50,
'resnet101': 101,
'resnet152': 152}
if backbone not in resnets:
raise ValueError("{} is not a valid resnet".format(backbone))
if num_input_images > 1:
self.encoder = resnets[backbone](pretrained=False, ctx=ctx, **kwargs)
if pretrained:
filename = os.path.join(
root, 'resnet%d_v%db_multiple_inputs.params' % (num_layers[backbone], 1))
if not os.path.isfile(filename):
from ..model_store import get_model_file
loaded = mx.nd.load(get_model_file('resnet%d_v%db' % (num_layers[backbone], 1),
tag=pretrained, root=root))
loaded['conv1.weight'] = mx.nd.concat(
*([loaded['conv1.weight']] * num_input_images), dim=1) / num_input_images
mx.nd.save(filename, loaded)
self.encoder.load_parameters(filename, ctx=ctx)
from ...data import ImageNet1kAttr
attrib = ImageNet1kAttr()
self.encoder.synset = attrib.synset
self.encoder.classes = attrib.classes
self.encoder.classes_long = attrib.classes_long
else:
self.encoder = resnets[backbone](pretrained=pretrained, ctx=ctx, **kwargs)
if backbone not in ('resnet18', 'resnet34'):
self.num_ch_enc[1:] *= 4
def hybrid_forward(self, F, input_image):
self.features = []
x = (input_image - 0.45) / 0.225
x = self.encoder.conv1(x)
x = self.encoder.bn1(x)
self.features.append(self.encoder.relu(x))
self.features.append(self.encoder.layer1(self.encoder.maxpool(self.features[-1])))
self.features.append(self.encoder.layer2(self.features[-1]))
self.features.append(self.encoder.layer3(self.features[-1]))
self.features.append(self.encoder.layer4(self.features[-1]))
return self.features
解码器模块是一个带有跳跃连接的全卷积网络,它利用不同尺度的特征图,并在上采样后进行拼接。最后一层使用 sigmoid 激活函数。它将输出限制在 [0, 1] 范围内,这意味着深度解码器输出的是归一化的视差图。
它定义如下:
class DepthDecoder(nn.HybridBlock):
def __init__(self, num_ch_enc, scales=range(4), num_output_channels=1,
use_skips=True):
super(DepthDecoder, self).__init__()
self.num_output_channels = num_output_channels
self.use_skips = use_skips
self.upsample_mode = 'nearest'
self.scales = scales
self.num_ch_enc = num_ch_enc
self.num_ch_dec = np.array([16, 32, 64, 128, 256])
# decoder
with self.name_scope():
self.convs = OrderedDict()
for i in range(4, -1, -1):
# upconv_0
num_ch_in = self.num_ch_enc[-1] if i == 4 else self.num_ch_dec[i + 1]
num_ch_out = self.num_ch_dec[i]
self.convs[("upconv", i, 0)] = ConvBlock(num_ch_in, num_ch_out)
# upconv_1
num_ch_in = self.num_ch_dec[i]
if self.use_skips and i > 0:
num_ch_in += self.num_ch_enc[i - 1]
num_ch_out = self.num_ch_dec[i]
self.convs[("upconv", i, 1)] = ConvBlock(num_ch_in, num_ch_out)
for s in self.scales:
self.convs[("dispconv", s)] = Conv3x3(
self.num_ch_dec[s], self.num_output_channels)
# register blocks
for k in self.convs:
self.register_child(self.convs[k])
self.decoder = nn.HybridSequential()
self.decoder.add(*list(self.convs.values()))
self.sigmoid = nn.Activation('sigmoid')
def hybrid_forward(self, F, input_features):
self.outputs = []
# decoder
x = input_features[-1]
for i in range(4, -1, -1):
x = self.convs[("upconv", i, 0)](x)
x = [F.UpSampling(x, scale=2, sample_type='nearest')]
if self.use_skips and i > 0:
x += [input_features[i - 1]]
x = F.concat(*x, dim=1)
x = self.convs[("upconv", i, 1)](x)
if i in self.scales:
self.outputs.append(self.sigmoid(self.convs[("dispconv", i)](x)))
return self.outputs
PoseNet 解码器模块是一个全卷积网络,它使用轴角表示法预测旋转,并将旋转和平移输出按 0.01 缩放。
它定义如下:
class PoseDecoder(nn.HybridBlock):
def __init__(self, num_ch_enc, num_input_features, num_frames_to_predict_for=2, stride=1):
super(PoseDecoder, self).__init__()
self.num_ch_enc = num_ch_enc
self.num_input_features = num_input_features
if num_frames_to_predict_for is None:
num_frames_to_predict_for = num_input_features - 1
self.num_frames_to_predict_for = num_frames_to_predict_for
self.convs = OrderedDict()
self.convs[("squeeze")] = nn.Conv2D(
in_channels=self.num_ch_enc[-1], channels=256, kernel_size=1)
self.convs[("pose", 0)] = nn.Conv2D(
in_channels=num_input_features * 256, channels=256,
kernel_size=3, strides=stride, padding=1)
self.convs[("pose", 1)] = nn.Conv2D(
in_channels=256, channels=256, kernel_size=3, strides=stride, padding=1)
self.convs[("pose", 2)] = nn.Conv2D(
in_channels=256, channels=6 * num_frames_to_predict_for, kernel_size=1)
# register blocks
for k in self.convs:
self.register_child(self.convs[k])
self.net = nn.HybridSequential()
self.net.add(*list(self.convs.values()))
def hybrid_forward(self, F, input_features):
last_features = [f[-1] for f in input_features]
cat_features = [F.relu(self.convs["squeeze"](f)) for f in last_features]
cat_features = F.concat(*cat_features, dim=1)
out = cat_features
for i in range(3):
out = self.convs[("pose", i)](out)
if i != 2:
out = F.relu(out)
out = out.mean(3).mean(2)
out = 0.01 * out.reshape(-1, self.num_frames_to_predict_for, 1, 6)
axisangle = out[..., :3]
translation = out[..., 3:]
return axisangle, translation
Monodepth 模型在 gluoncv.model_zoo.MonoDepth2 中提供,PoseNet 在 gluoncv.model_zoo.MonoDepth2PoseNet 中提供。要获取使用 ResNet18 作为基础网络的 Monodepth2 模型,请执行以下操作:
model = gluoncv.model_zoo.get_monodepth2(backbone='resnet18')
print(model)
输出
MonoDepth2(
(encoder): ResnetEncoder(
(encoder): ResNetV1b(
(conv1): Conv2D(3 -> 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu): Activation(relu)
(maxpool): MaxPool2D(size=(3, 3), stride=(2, 2), padding=(1, 1), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(layer1): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
)
(1): BasicBlockV1b(
(conv1): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
)
)
(layer2): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(64 -> 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(64 -> 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
)
)
(1): BasicBlockV1b(
(conv1): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
)
)
(layer3): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(128 -> 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(128 -> 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
)
)
(1): BasicBlockV1b(
(conv1): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
)
)
(layer4): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(256 -> 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(256 -> 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
)
)
(1): BasicBlockV1b(
(conv1): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
)
)
(avgpool): GlobalAvgPool2D(size=(1, 1), stride=(1, 1), padding=(0, 0), ceil_mode=True, global_pool=True, pool_type=avg, layout=NCHW)
(flat): Flatten
(fc): Dense(512 -> 1000, linear)
)
)
(decoder): DepthDecoder(
(decoder): HybridSequential(
(0): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(512 -> 256, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(1): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(512 -> 256, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(2): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(256 -> 128, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(3): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(256 -> 128, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(4): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(128 -> 64, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(5): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(128 -> 64, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(6): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(64 -> 32, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(7): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(96 -> 32, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(8): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(32 -> 16, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(9): ConvBlock(
(conv): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(16 -> 16, kernel_size=(3, 3), stride=(1, 1))
)
(nonlin): ELU(
)
)
(10): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(16 -> 1, kernel_size=(3, 3), stride=(1, 1))
)
(11): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(32 -> 1, kernel_size=(3, 3), stride=(1, 1))
)
(12): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(64 -> 1, kernel_size=(3, 3), stride=(1, 1))
)
(13): Conv3x3(
(pad): ReflectionPad2D(
)
(conv): Conv2D(128 -> 1, kernel_size=(3, 3), stride=(1, 1))
)
)
(sigmoid): Activation(sigmoid)
)
)
要获取使用 ResNet18 作为基础网络的 PoseNet,请执行以下操作:
posenet = gluoncv.model_zoo.get_monodepth2posenet(backbone='resnet18')
print(posenet)
输出
MonoDepth2PoseNet(
(encoder): ResnetEncoder(
(encoder): ResNetV1b(
(conv1): Conv2D(6 -> 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu): Activation(relu)
(maxpool): MaxPool2D(size=(3, 3), stride=(2, 2), padding=(1, 1), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(layer1): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
)
(1): BasicBlockV1b(
(conv1): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu1): Activation(relu)
(conv2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=64)
(relu2): Activation(relu)
)
)
(layer2): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(64 -> 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(64 -> 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
)
)
(1): BasicBlockV1b(
(conv1): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu1): Activation(relu)
(conv2): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=128)
(relu2): Activation(relu)
)
)
(layer3): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(128 -> 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(128 -> 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
)
)
(1): BasicBlockV1b(
(conv1): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu1): Activation(relu)
(conv2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=256)
(relu2): Activation(relu)
)
)
(layer4): HybridSequential(
(0): BasicBlockV1b(
(conv1): Conv2D(256 -> 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
(downsample): HybridSequential(
(0): Conv2D(256 -> 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
)
)
(1): BasicBlockV1b(
(conv1): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu1): Activation(relu)
(conv2): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(relu2): Activation(relu)
)
)
(avgpool): GlobalAvgPool2D(size=(1, 1), stride=(1, 1), padding=(0, 0), ceil_mode=True, global_pool=True, pool_type=avg, layout=NCHW)
(flat): Flatten
(fc): Dense(512 -> 1000, linear)
)
)
(decoder): PoseDecoder(
(net): HybridSequential(
(0): Conv2D(512 -> 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2D(256 -> 12, kernel_size=(1, 1), stride=(1, 1))
)
)
)
数据集和数据增强¶
准备 KITTI RAW 数据集
这里我们给出一个在 KITTI RAW 数据集 [Godard19] 上训练 monodepth2 的示例。首先,我们需要准备数据集。monodepth2 的官方实现没有使用 KITTI RAW 数据集的所有数据,这里我们使用与 [Godard19] 相同的数据集和分割方法。您需要下载分割的 zip 文件,并将其解压到
$(HOME)/.mxnet/datasets/kitti/。按照命令获取数据集
cd ~ mkdir -p .mxnet/datasets/kitti cd .mxnet/datasets/kitti wget https://github.com/KuangHaofei/GluonCV_Test/raw/master/monodepthv2/tutorials/splits.zip unzip splits.zip wget -i splits/kitti_archives_to_download.txt -P kitti_data/ cd kitti_data unzip "*.zip"
提示
您需要 175GB 可用磁盘空间来下载和解压此数据集。建议使用 SSD 硬盘以获得更快的速度。准备数据集所需的时间取决于您的互联网连接和磁盘速度。例如,在具有 EBS 的 AWS EC2 实例上大约需要 2 小时。
我们在 gluoncv.data 中提供了自监督深度估计数据集。
例如,我们可以轻松获取 KITTI RAW Stereo 数据集
import os
from gluoncv.data.kitti import readlines, dict_batchify_fn
train_filenames = os.path.join(
os.path.expanduser("~"), '.mxnet/datasets/kitti/splits/eigen_full/train_files.txt')
train_filenames = readlines(train_filenames)
train_dataset = gluoncv.data.KITTIRAWDataset(
filenames=train_filenames, height=192, width=640,
frame_idxs=[0, -1, 1, "s"], num_scales=4, is_train=True, img_ext='.png')
print('Training images:', len(train_dataset))
# set batch_size = 12 for toy example
batch_size = 12
train_loader = gluon.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, batchify_fn=dict_batchify_fn,
num_workers=12, pin_memory=True, last_batch='discard')
这里,frame_idxs 参数用于决定输入帧。它是一个列表,第一个元素必须是 0,表示源帧。其他元素表示目标帧。数值表示图像序列中的相对帧 ID。“s” 表示立体对中源图像的另一侧。
数据增强
我们遵循标准的数据增强流程来转换输入图像。这里,我们只对输入图像使用 50% 概率的 RandomFlip。
随机选择一个示例进行可视化
import random
from datetime import datetime
random.seed(datetime.now())
idx = random.randint(0, len(train_dataset))
data = train_dataset[idx]
input_img = data[("color", 0, 0)]
input_stereo_img = data[("color", 's', 0)]
input_gt = data['depth_gt']
input_img = np.transpose((input_img.asnumpy() * 255).astype(np.uint8), (1, 2, 0))
input_stereo_img = np.transpose((input_stereo_img.asnumpy() * 255).astype(np.uint8), (1, 2, 0))
input_gt = np.transpose((input_gt.asnumpy()).astype(np.uint8), (1, 2, 0))
from PIL import Image
input_img = Image.fromarray(input_img)
input_stereo_img = Image.fromarray(input_stereo_img)
input_gt = Image.fromarray(input_gt[:, :, 0])
input_img.save("input_img.png")
input_stereo_img.save("input_stereo_img.png")
input_gt.save("input_gt.png")
绘制立体图像对和左侧图像的真实深度
from matplotlib import pyplot as plt
input_img = Image.open('input_img.png').convert('RGB')
input_stereo_img = Image.open('input_stereo_img.png').convert('RGB')
input_gt = Image.open('input_gt.png')
fig = plt.figure()
# subplot 1 for left image
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=0.75)
fig.add_subplot(3, 1, 1)
plt.title("left image")
plt.imshow(input_img)
# subplot 2 for right images
fig.add_subplot(3, 1, 2)
plt.title("right image")
plt.imshow(input_stereo_img)
# subplot 3 for the ground truth
fig.add_subplot(3, 1, 3)
plt.title("ground truth of left input (the reprojection of LiDAR data)")
plt.imshow(input_gt)
# display
plt.show()
Dataloader 将提供一个字典,其中包括原始图像、增强图像、相机内参、相机外参(立体)和真实深度图(用于验证)。
训练细节¶
预测相机姿态
在单目或单目+立体模式下训练网络时,我们必须通过 PoseNet 获取预测的相机姿态。
损失的预测定义如下(请查看完整的 trainer.py 以获得完整实现。)
def predict_poses(self, inputs):
outputs = {}
pose_feats = {f_i: inputs["color_aug", f_i, 0] for f_i in self.opt.frame_ids}
for f_i in self.opt.frame_ids[1:]:
if f_i != "s":
# To maintain ordering we always pass frames in temporal order
if f_i < 0:
pose_inputs = [pose_feats[f_i], pose_feats[0]]
else:
pose_inputs = [pose_feats[0], pose_feats[f_i]]
axisangle, translation = self.posenet(mx.nd.concat(*pose_inputs, dim=1))
outputs[("axisangle", 0, f_i)] = axisangle
outputs[("translation", 0, f_i)] = translation
# Invert the matrix if the frame id is negative
outputs[("cam_T_cam", 0, f_i)] = transformation_from_parameters(
axisangle[:, 0], translation[:, 0], invert=(f_i < 0))
return outputs
图像重建
为了通过自监督方式训练网络,我们必须根据预测的深度和姿态(或使用立体对的相机外参)从目标图像重建源图像。然后,计算重建的源图像与真实源图像之间的重投影光度损失。
整个过程分为三个步骤:
根据深度和相机内参将目标图像的每个点反投影到 3D 空间;
根据相机外参(姿态)和内参将 3D 点投影到图像平面;
根据投影点从源图像采样像素以重建新图像(利用空间变换网络(STN)确保采样是可微分的)。
反投影(2D 到 3D)定义如下:
class BackprojectDepth(nn.HybridBlock):
"""Layer to transform a depth image into a point cloud
"""
def __init__(self, batch_size, height, width, ctx=mx.cpu()):
super(BackprojectDepth, self).__init__()
self.batch_size = batch_size
self.height = height
self.width = width
self.ctx = ctx
meshgrid = np.meshgrid(range(self.width), range(self.height), indexing='xy')
id_coords = np.stack(meshgrid, axis=0).astype(np.float32)
id_coords = mx.nd.array(id_coords).as_in_context(self.ctx)
pix_coords = mx.nd.expand_dims(mx.nd.stack(*[id_coords[0].reshape(-1),
id_coords[1].reshape(-1)], axis=0),
axis=0)
pix_coords = pix_coords.repeat(repeats=batch_size, axis=0)
pix_coords = pix_coords.as_in_context(self.ctx)
with self.name_scope():
self.id_coords = self.params.get('id_coords', shape=id_coords.shape,
init=mx.init.Zero(), grad_req='null')
self.id_coords.initialize(ctx=self.ctx)
self.id_coords.set_data(mx.nd.array(id_coords))
self.ones = self.params.get('ones',
shape=(self.batch_size, 1, self.height * self.width),
init=mx.init.One(), grad_req='null')
self.ones.initialize(ctx=self.ctx)
self.pix_coords = self.params.get('pix_coords',
shape=(self.batch_size, 3, self.height * self.width),
init=mx.init.Zero(), grad_req='null')
self.pix_coords.initialize(ctx=self.ctx)
self.pix_coords.set_data(mx.nd.concat(pix_coords, self.ones.data(), dim=1))
def hybrid_forward(self, F, depth, inv_K, **kwargs):
cam_points = F.batch_dot(inv_K[:, :3, :3], self.pix_coords.data())
cam_points = depth.reshape(self.batch_size, 1, -1) * cam_points
cam_points = F.concat(cam_points, self.ones.data(), dim=1)
return cam_points
投影(3D 到 2D)定义如下:
class Project3D(nn.HybridBlock):
"""Layer which projects 3D points into a camera with intrinsics K and at position T
"""
def __init__(self, batch_size, height, width, eps=1e-7):
super(Project3D, self).__init__()
self.batch_size = batch_size
self.height = height
self.width = width
self.eps = eps
def hybrid_forward(self, F, points, K, T):
P = F.batch_dot(K, T)[:, :3, :]
cam_points = F.batch_dot(P, points)
cam_pix = cam_points[:, :2, :] / (cam_points[:, 2, :].expand_dims(1) + self.eps)
cam_pix = cam_pix.reshape(self.batch_size, 2, self.height, self.width)
x_src = cam_pix[:, 0, :, :] / (self.width - 1)
y_src = cam_pix[:, 1, :, :] / (self.height - 1)
pix_coords = F.concat(x_src.expand_dims(1), y_src.expand_dims(1), dim=1)
pix_coords = (pix_coords - 0.5) * 2
return pix_coords
图像重建函数定义如下(请查看完整的 trainer.py 以获得完整实现。)
def generate_images_pred(self, inputs, outputs):
for scale in self.opt.scales:
disp = outputs[("disp", scale)]
if self.opt.v1_multiscale:
source_scale = scale
else:
disp = mx.nd.contrib.BilinearResize2D(disp,
height=self.opt.height,
width=self.opt.width)
source_scale = 0
_, depth = disp_to_depth(disp, self.opt.min_depth, self.opt.max_depth)
outputs[("depth", 0, scale)] = depth
for i, frame_id in enumerate(self.opt.frame_ids[1:]):
if frame_id == "s":
T = inputs["stereo_T"]
else:
T = outputs[("cam_T_cam", 0, frame_id)]
cam_points = self.backproject_depth[source_scale](depth,
inputs[("inv_K", source_scale)])
pix_coords = self.project_3d[source_scale](cam_points,
inputs[("K", source_scale)],
T)
outputs[("sample", frame_id, scale)] = pix_coords
outputs[("color", frame_id, scale)] = mx.nd.BilinearSampler(
data=inputs[("color", frame_id, source_scale)],
grid=outputs[("sample", frame_id, scale)],
name='sampler')
if not self.opt.disable_automasking:
outputs[("color_identity", frame_id, scale)] = \
inputs[("color", frame_id, source_scale)]
训练损失
我们应用标准的重投影损失来训练 Monodepth2。正如 Monodepth2 [Godard19] 所述,重投影损失包括三部分:多尺度重投影光度损失(结合了 L1 损失和 SSIM 损失)、自动遮罩损失以及 Monodepth [Godard17] 中的边缘感知平滑损失。
损失的计算定义如下(请查看完整的 trainer.py 以获得完整实现。)
def compute_losses(self, inputs, outputs):
"""Compute the reprojection and smoothness losses for a minibatch
"""
losses = {}
total_loss = 0
for scale in self.opt.scales:
loss = 0
reprojection_losses = []
if self.opt.v1_multiscale:
source_scale = scale
else:
source_scale = 0
disp = outputs[("disp", scale)]
color = inputs[("color", 0, scale)]
target = inputs[("color", 0, source_scale)]
for frame_id in self.opt.frame_ids[1:]:
pred = outputs[("color", frame_id, scale)]
reprojection_losses.append(self.compute_reprojection_loss(pred, target))
reprojection_losses = mx.nd.concat(*reprojection_losses, dim=1)
if not self.opt.disable_automasking:
identity_reprojection_losses = []
for frame_id in self.opt.frame_ids[1:]:
pred = inputs[("color", frame_id, source_scale)]
identity_reprojection_losses.append(
self.compute_reprojection_loss(pred, target))
identity_reprojection_losses = mx.nd.concat(*identity_reprojection_losses, dim=1)
if self.opt.avg_reprojection:
identity_reprojection_loss = \
identity_reprojection_losses.mean(axis=1, keepdims=True)
else:
# save both images, and do min all at once below
identity_reprojection_loss = identity_reprojection_losses
if self.opt.avg_reprojection:
reprojection_loss = reprojection_losses.mean(axis=1, keepdims=True)
else:
reprojection_loss = reprojection_losses
if not self.opt.disable_automasking:
# add random numbers to break ties
identity_reprojection_loss = \
identity_reprojection_loss + \
mx.nd.random.randn(*identity_reprojection_loss.shape).as_in_context(
identity_reprojection_loss.context) * 0.00001
combined = mx.nd.concat(identity_reprojection_loss, reprojection_loss, dim=1)
else:
combined = reprojection_loss
if combined.shape[1] == 1:
to_optimise = combined
else:
to_optimise = mx.nd.min(data=combined, axis=1)
idxs = mx.nd.argmin(data=combined, axis=1)
if not self.opt.disable_automasking:
outputs["identity_selection/{}".format(scale)] = (
idxs > identity_reprojection_loss.shape[1] - 1).astype('float')
loss += to_optimise.mean()
mean_disp = disp.mean(axis=2, keepdims=True).mean(axis=3, keepdims=True)
norm_disp = disp / (mean_disp + 1e-7)
smooth_loss = get_smooth_loss(norm_disp, color)
loss = loss + self.opt.disparity_smoothness * smooth_loss / (2 ** scale)
total_loss = total_loss + loss
losses["loss/{}".format(scale)] = loss
total_loss = total_loss / self.num_scales
losses["loss"] = total_loss
return losses
学习率和调度
这里,我们遵循 monodepth2 的标准策略。网络使用 Adam 训练 20 个 epoch。我们使用“步进”学习率调度器进行 Monodepth2 训练,该调度器在
gluoncv.utils.LRScheduler中提供。前 15 个 epoch 使用 10−4 的学习率,然后在剩余的 epoch 中降低到 10−5。
优化示例定义如下:
lr_scheduler = gluoncv.utils.LRSequential([
gluoncv.utils.LRScheduler(
'step', base_lr=1e-4, nepochs=20, iters_per_epoch=len(train_dataset), step_epoch=[15])
])
optimizer_params = {'lr_scheduler': lr_scheduler,
'learning_rate': 1e-4}
创建 Adam 优化器
深度和姿态优化器的示例定义如下:
训练循环¶
请查看完整的 trainer.py 以获得完整实现。这是一个训练循环的示例:
def train(self):
"""Run the entire training pipeline
"""
self.logger.info('Starting Epoch: %d' % self.opt.start_epoch)
self.logger.info('Total Epochs: %d' % self.opt.num_epochs)
self.epoch = 0
for self.epoch in range(self.opt.start_epoch, self.opt.num_epochs):
self.run_epoch()
self.val()
# save final model
self.save_model("final")
self.save_model("best")
def run_epoch(self):
"""Run a single epoch of training and validation
"""
print("Training")
tbar = tqdm(self.train_loader)
train_loss = 0.0
for batch_idx, inputs in enumerate(tbar):
with autograd.record(True):
outputs, losses = self.process_batch(inputs)
mx.nd.waitall()
autograd.backward(losses['loss'])
self.depth_optimizer.step(self.opt.batch_size, ignore_stale_grad=True)
if self.use_pose_net:
self.pose_optimizer.step(self.opt.batch_size, ignore_stale_grad=True)
train_loss += losses['loss'].asscalar()
tbar.set_description('Epoch %d, training loss %.3f' % \
(self.epoch, train_loss / (batch_idx + 1)))
if batch_idx % self.opt.log_frequency == 0:
self.logger.info('Epoch %d iteration %04d/%04d: training loss %.3f' %
(self.epoch, batch_idx, len(self.train_loader),
train_loss / (batch_idx + 1)))
mx.nd.waitall()
您可以立即开始训练。
参考文献¶
- Godard17
Clement Godard, Oisin Mac Aodha 和 Gabriel J. Brostow “Unsupervised Monocular Depth Estimation with Left-Right Consistency.” Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2017.
- Godard19(1,2,3,4)
Clement Godard, Oisin Mac Aodha, Michael Firman 和 Gabriel Brostow. “Digging Into Self-Supervised Monocular Depth Estimation.” Proceedings of the IEEE conference on computer vision (ICCV). 2019.
脚本总运行时间: ( 0 minutes 0.262 seconds)